Table of Contents
Abstract
JEmacs is a re-implementation of the Emacs programmable text editor. It is written in Java, and currently uses the Swing GUI toolkit. Emacs is based on the extension language Emacs Lisp (Elisp), which is a dynamically-scoped member of the Lisp family. JEmacs supports Elisp, as well as the use of Scheme, a more modern statically-scoped Lisp dialect. Both languages get compiled to Java bytecodes, either in advance or on-the-fly, using the Kawa compilation framework.
This article is an update of a paper presented at the 2000 Usenix conference.
Emacs [Emacs] [EmacsManual] (in various versions) is a popular programmer's text editor. Emacs is programmable using ‘Emacs Lisp’ (Elisp) [Elisp] and many powerful packages are written in Elisp. The Free Software Foundation has a goal to replace Elisp with Scheme while also providing a translator to convert old Elisp files to Scheme. One reason is that Elisp is an ad-hoc, non-standard Lisp variant not used anywhere else, and not consistent with modern programming-language ideas. Another reason is that Guile, the primary GNU dialect of Scheme, is intended to be the standard extension language for GNU software, and so it makes sense for Emacs (the main GNU application with extensive use of a scripting language) to follow suit.
My opinion is that Guile is not the best Scheme implementation to use for Emacs. I happen to be biased, as I am the author of Kawa, a Java-based Scheme implementation. I also think that just replacing the extension language may not go far enough, and perhaps it is time to also replace the low-level code written in C.
Therefore, I have been working on a ‘next-generation’ Emacs, based on Java and Kawa. The design includes:
An implementation of the Scheme language.
An implementation of the Elisp (core) syntax and language, such as functions used for creating lists and strings, defining functions, and macros.
A set of abstract Java classes that implement the Emacs “editing types”, such as EBuffer, EWindow, EKeymap, and EMarker.
A set of Java concrete (implementation) classes that implement the above abstract classes using the Swing GUI api, such as SwingBuffer, and SwingWindow.
A set of Scheme bindings to the Java methods. These are “similar to” and have the same names as standard Emacs Lisp functions, but are written in Scheme and intended to be called from Scheme.
The equivalent Elisp functions: Implementations of the high-level Emacs functions as Elisp functions, so existing Elisp applications can (mostly) run without change.
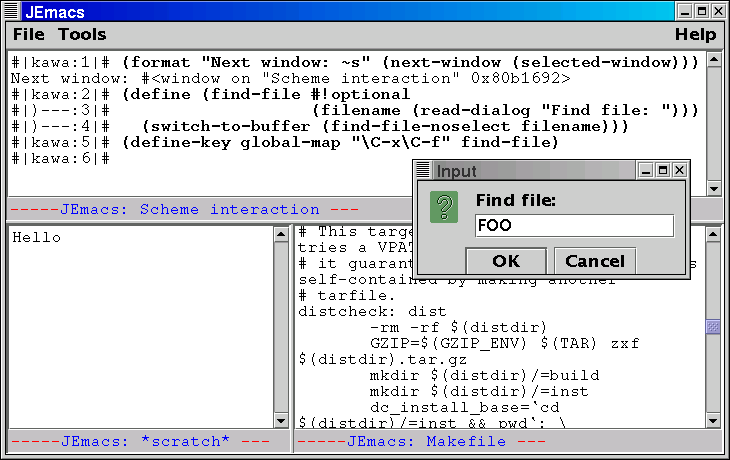
This is a major, perhaps foolhardy, undertaking. Here are some reasons why it might make sense; I expand on these later.
Kawa is a modern object-oriented Scheme, while Emacs is based on rather old design ideas.
Building on a Java run-time means we benefit from the work being done to run Java bytecodes fast.
Java is multi-threaded.
Java is based on Unicode and has good internationalization support.
Java has lots of neat packages we can use.
Swing is a modern GUI toolkit with good support for major Emacs concepts. It would be useful to have Scheme (and Elisp) scripting for Swing applications.
The most visible part of Kawa (see [Bothner98a], [Bothner98b]) is an implementation of the Scheme programming language written in Java. I have been developing Kawa since 1996. Unlike other such implementations, Kawa compiles Scheme into Java bytecodes, with non-trivial optimizations. It also provides almost all the other features you expect from a production Scheme system (including eval and load) and convenient interaction between Scheme and Java.
Kawa is also a framework used to implement Scheme, and which can be used for other languages. The package gnu.bytecode provides classes to generate Java .class bytecode files, including methods to generate the Java virtual machine instructions. It also lets you read, print, and otherwise manipulate the Java .class file format. At a higher level, the gnu.expr package works on Expression objects. This is basically an abstract syntax tree (AST) representation, and the package has classes to generate and optimize expressions and declarations. It uses the gnu.bytecode package to generate bytecodes from the Expression representation.
The Kawa framework was originally used to compile Scheme. However, I wrote the beginnings of an EcmaScript (JavaScript) implementation, and others are using Kawa to compile other languages, including BRL (http://brl.sourceforge.net/) and Nice (http://nice.sourceforge.net). Currenty, I am using Kawa to implement XQuery (http://www.qexo.org/), the new XML Query language from the World Wide Web Consortium. For the JEmacs project, the framework is being used to compile Emacs Lisp to Java bytecodes, replacing the Emacs byte-compiler: Instead of .elc files loaded into the Emacs bytecode interpreter, we use Java bytecode (.class) files loaded into a Java Virtual Machine. Kawa also includes the beginnings of a Common Lisp implementation, which shares some code with the Emacs Lisp implementation.
A primary advantage of JEmacs is that Kawa is potentially much faster than either Elisp or Guile. Using an optimizing compiler that compiles to bytecode is certainly going to be faster than Guile or Emacs's simple interpreter. The Emacs bytecode-compiler uses the same idea, and produces a bytecode format that is more suitable to Emacs than Java bytecodes. However, there are many projects and companies working very hard on running Java bytecodes fast. The common approach is to use a ‘Just-in-Time compiler’ (JIT), which dynamically compiles a bytecode method into native code inside the runtime. Another approach is to use a traditional ‘ahead-of-time’ compiler (such as the Gcc-based Gcj [Bothner97]). It thus seems plausible (though unproven) that JEmacs can achieve better performance than Emacs.
Sun introduced Swing [SwingTutorial] in 1998 as the ‘next-generation’ GUI toolkit for Java. Swing has a lot of functionality and many useful features. It builds on the earlier AWT (Abstract Windowing Toolkit). Of particular interest is that the text support in Swing is both very powerful, and also seems to be inspired by Emacs ideas. Swing has new ‘widgets’ based on separating the ‘model’ (data) and ‘view+control’ (look+feel). For example, Swing distinguishes between a Document versus a JTextComponent that displays the Document, which is essentially the same as the Emacs buffer versus window distinction. Swing also has a Keymap class similar to that of Emacs, and a Position that is like an Emacs marker.
Swing has some other nice features, such as ‘pluggable-look-and-feel’ (themeability), a number of flexible ‘widgets’, and support for ‘structured’ documents (i.e. XML/HTML structure in a buffer).
The biggest problem with Swing is that while it is portable and freely redistributable, it does not have a free license. This also makes debugging JEmacs difficult, since we cannot study the Swing source code to see what is going on. There have been some recents starts at free re-implementations of Swing, but anything useful seems a long way off.
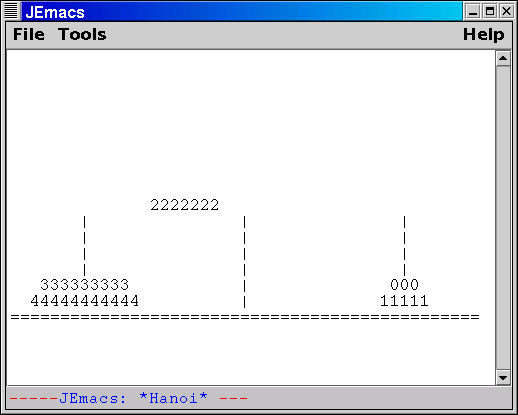
Another possible problem with Swing is performance. Swing is huge, and has the reputation of being slow. The first Emacs package ported to JEmacs (Towers-of-Hanoi animation) does run slower than under XEmacs. The cause of this is not clear, but it is quite possible it is due to Swing overheads. It may be possible to improve the situation with more low-level Swing coding. Swing is very flexible in this respect, because the API uses mostly abstract interfaces, rather than specific implementation classes, and the latter can be replaced.
I have recently (March 2002) started separating out the Swing-specific implementation classes from the Swing-independent logic. The various Emacs types like EBuffer will become abstract classes or interfaces. Most of JEmacs, including all the Elisp, references these abstract classes, without caring about the specific implementation classes. The first set of implementation classes will be based on the old Swing implementation, but the goal is to add other implementations using other toolkits, perhaps even curses.
I would like to see a JEmacs implementation based on the Gnome 2 text widgets. This supports the needed model-view separation, using a GtkTextView widget to implement an Emacs window, and a GtkTextBuffer to implement an Emacs buffer. An Emacs marker can be implemented using a GtkTextMark. GtkTextBuffer uses the Pango library and supports embedded images and widgets, multiple styles and fonts, and complex scripts, including bi-directional text, and complex character compositioning.
Another widget set worth examining is SWT, part of the Eclipse project.
One problem with traditional Emacs is that it is single-threaded. If you start some non-trivial operation (such as getting new mail), your Emacs session will be frozen until the operation completes. Java is designed to be multi-threaded, so it is in theory straightforward to create a multi-threaded Emacs.
One complication is that the Emacs Lisp execution model is inherently single threaded, since any Elisp function can change the current buffer or window to another buffer or window, while in the middle of the function. This means we cannot associate a thread with each buffer or with each window.
A solution to this problem is to use ‘buffer groups’, that is a group of related buffers and their windows which run in the same thread. Typically, there would be one buffer group for each Elisp ‘application’. By default, when an Elisp function creates a new buffer, it is put in the same buffer group as the the current buffer. However, an Elisp function such as find-file can create a new buffer group when it creates a new buffer.
Another problem is that Swing itself is single-threaded. Only one thread (the event thread) can safely modify a buffer that is visible in a window. In the current JEmacs implementation all interactive commands are run by the event thread. Thus effectively, all of JEmacs is running inside the event thread. A solution is for long-running commands to use a ‘worker’ thread. When the worker thread is finished, it lets the event thread know it is done, which can then update the buffers and display.
The following Java classes in the gnu.jemacs.buffer package implement what we might call the Emacs data ‘model’.
EBuffer: An Emacs buffer. Contains the actual text and styles of the buffer, though the actual data representation is handled by derived classes. Also contains other buffer properties, such as the buffer's keymap(s). Inherits from gnu.lists.AbstractSequence, which is part of the Kawa collections framework.
EMarker: A position in a buffer that gets adjusted as needed. Similar to the Swing Position class, but also knows the EBuffer it points to.
The following Java classes implement what we might call the Emacs ‘view+controller’.
EWindow: An Emacs Window. Abstract class. Contains a pointer to the buffer that is displayed in this window.
EFrame: A top-level window. A Frame manages a nested hierarchy of EWindow objects.
EKeymap: A data structure used to map into events to commands. The input events are represented as 32-bit integers encoding the character or the keycode typed and the modifier bits (shift, control etc).
These are the main Swing-specific implementation classes, and are in the gnu.jemacs.swing package.
SwingBuffer: Extends the EBuffer class. Uses an instance of Swing's DefaultStyledDocument to contain the actual text and styles.
SwingContent: A Swing Document uses a separate Content object to store the actual character data (but not the styles). This class is needed because standard Swing Content implementation does not support the Marker semantics we need.
SwingWindow: Extends the EWindow class. Uses a Swing JtextPane instance. Implements the java.awt.event.KeyListener interface; this is used to handle keyboard input and mouse clicks. The actual action to perform is found by searching EKeymap objects belonging to the associated Buffer. Includes an assocated Modeline, and a scrollbar.
SwingFrame: Extends the EFrame class. Uses Swing's JSplitPane class to sub-divide a top-level JFrame.
JEmacs includes a number of Scheme procedures for operating on the Java classes just mentioned. The Scheme API is designed to be similar to the traditional Elisp functions, but in Scheme form. Here is the JEmacs definition of the standard Emacs function beginning-of-line, written in Scheme.
(define (beginning-of-line
#!optional
(n :: <int> 1)
(buffer :: <buffer>
(current-buffer)))
(invoke buffer 'setPoint
(point-at-bol n buffer)))
(define-key global-map "\C-a"
beginning-of-line)
Note the optional type declarations for the two parameters. Also note the invoke ‘function’. This calls the specified method (in this case setPoint) on the specified object (in this case the buffer). In a case like this where the receiver class is known, the Kawa compiler can directly generate a invokevirtual bytecode instruction.
Once we have defined beginning-of-line, it can be used from either Elisp or Scheme code. This makes it easier to mix Scheme and Elisp, convert (if desired) Elisp to Scheme, and lets us re-use Elisp documentation.
Our goal is to be able to run most Elisp package unmodified. Some packages may require minor changes, but no more than say porting to XEmacs. The first Emacs package that runs under JEmacs without requiring a single modification to the Elisp source is hanoi.el, an animation of the Towers-of-Hanoi puzzle. However, it may be desirable to rewrite some packages, possibly in Scheme or Java. For example, dired needs a more modern interface.
The Scheme and Elisp APIs implemented in JEmacs are based on those of both GNU Emacs and XEmacs. JEmacs will not implement either API exactly, but will try to implement the features that make most sense. For example, GNU Emacs and XEmacs have very different APIs for manipulating the menubar. In this case, JEmacs implemented a menubar API based on the XEmacs API, partly because it was closer to the Swing menubar model.
There are some tricky issues if you want to implement Elisp, especially if you want nice interoperability with Scheme. (The plan for GNU Emacs is to translate Elisp into Scheme, which raises similar issues.)
While both Scheme and Elisp share the fully parenthesized prefix notation common to the Lisp family, there are some differences in the syntax of literals and identifiers. For example, the character 'a' is written #\a in Scheme, and ?a in Elisp. The part of a Lisp system that converts a stream of characters to a value (usually a linked list) is traditionally called the “reader”. I had to write an Elisp reader to go along with the Scheme reader, and make sure the right one is invoked.
Once the reader has converted an input line or file to a list, the list needs to be converted into Kawa's internal Expression (abstract syntax tree) representation. This is handled similar for Elisp and Scheme. However, Elisp has some new syntax forms (such as defun, save-excursion) and and some forms that are different than in Scheme (such as lambda). For that we need to write new syntax transformers. This is almost done.
The symbol data type in Scheme is very simple: It is an immutable atomic string; you can create a symbol from a (mutable) string, and you can convert the symbol back to a string (for example for printing). Whenever you convert a string to a symbol, you will always get the same identical symbol, as long as the strings have the same characters. This process is called interning and is implemented using a global hash-table. Symbols are used for multiple purposes, but the most important one is that identifiers in a Scheme program are represented using symbols.
Java has a similar datatype, the class String, which is used all over the place in Java. Java has a method, called intern, which returns an interned version of the String. This functionality is exactly what is needed for Scheme, so Kawa uses String for Scheme symbols. This has the side benefit of increasing interoperabilty between Scheme and Java.
On the other hand, an Elisp symbol has extra properties: value and function bindings, and a property list. The traditional implementation is that a symbol value is a pointer to a structure containing the necessary fields. JEmacs uses this approach, which makes extracting the value and function bindings cheap, though it requires extra space in all symbols, and it complicates the Scheme/Elisp interface. The Binding class implements symbols. the Environment is basically a hashtable used to map a string to a Binding; it corresponds to the CommonLisp package concept.
In Elisp, the empty list and the symbol 'nil are the same object, but in Scheme they are different. There are various ways to deal with the problem, none particularly elegant. In Kawa, lists inherit from the abstract Sequence class. I feel it is important that the empty list also be a Sequence, even for Elisp, and it is important to be able to pass lists between Scheme and Elisp code. I decided that 'nil would have to be a special case: While the Elisp symbol t is represented using a Binding, the symbol nil is represented by the special LList value LList.Empty that Kawa uses for empty lists. Thus the predicate (symbolp x) is implemented as (x == List.Empty || x instanceof Binding).
Elisp has many builtin functions and macros which are different from Scheme. There is no fundamental difficulty with this; just a lot of porting/conversion work. Many of the basic editing functions are already implemented, but many (such as those involving searching) are not.
Variable lookup is different in Scheme and Elisp in two main ways: Elisp has different namespaces for function names and variable names, while Scheme has a single namespace for both. This is handled by using the appropriate field of the Binding. More troublesome is Elisp's use of dynamic scoping, while Scheme uses lexical scoping. Also, Emacs has buffer-local variables.
Kawa supports dynamic scoping using the fluid-name extension to Scheme. It is straight-forward for the Elisp compiler to translate Emacs local variable declarations (such as let and parameter specifications) as if they were fluid-name, and this works pretty well. However, there is some performance loss when using dynamic scoping compared to lexical scoping, and it turns out that the vast majority of local variables in Elisp code are really local, and would work the same if lexical scoping is used. The paper [DynamicScope] describes how one might do such an optimization.
Kawa actually has a very flexible name-binding mechanism based on storing a Constraint in each Binding. The constraint contains the actual methods that get/set the value of the Binding. For example, setting b to x does b.constraint.set(b, x). A Binding also has a property list (including the name) and a value field. The default action for get retrieves the Binding value field. Different sub-classes of Constraint have different implementations of get and set.
This framework can handle thread-local dynamic bindings, buffer-local variables, indirection, unbound variables (get throws an exception), and constraint propagation. Changing a value can trigger arbitrary checks or notification messages.
In Emacs, a mode is a set of keybindings, functions, and variables local to a buffer. There is no object corresponding to a ‘mode’, but there is a set of conventions to follow. In an object-oriented environment it seems better to define a separate mode class for each mode. Each buffer that has a mode enabled should have a corresponding mode instance.
Each buffer has a linked list of mode instances, one for each major/minor mode that is active for the buffer. Mode functions are compiled to virtual methods of the mode object. Instead of a buffer-local variable, use a field of the mode object. This provides fast access to variables in compiled code, without run-time symbol lookup. A derived mode can use mode class inheritance.
As an example, the abstract class ProcessMode inherits from the generic Mode class. A ProcessMode represents some kind of process which (usually) generates output that gets inserted into the buffer. Partial implementations exist of the sub-classes InfProcessMode, which displays the output of an external (possibly-interactive) program, and TelnetMode. Both of these provide minimal terminal emulation.
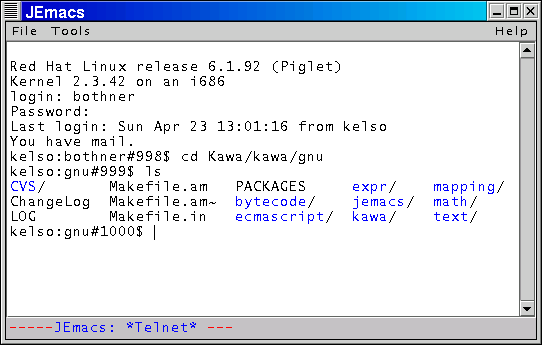
The Mode framework has been used for modes written directly in Java. It is now possible to write Java classes in Kawa Scheme, using the define-class special form. It seems reasonable to add a define-mode syntax form based on define-class. Of course existing (legacy) Elisp code does not use define-mode,but it should be possible for Kawa to recognize a (defun XXX-mode() BODY) that follows the standard Emacs conventions, and generate a Mode in that case. Alternatively, we can just support legacy code using more ad hoc mechanisms.
The Java char is a 16-bit Unicode character. Internal strings and JEmacs buffers use these Unicode chars. On the other hand, external files consist of 8-bit bytes. So Java provides named encodings that map byte streams and character streams.
Java with Swing handles much of the work needed for complex text processing. For example, bi-directional text (as needed for Hebrew and Arabic) is taken care of. In the screenshot below, we have a file encoded in UTF-8. It contains a string of four Hebrew characters, stored in the buffer in logical (reading) order. When they displayed, they are shown right-to-left. Notice that if you make a text selection that includes both English and Hebrew text, the selected characters form a contiguous region in the memory, but because different segments are displayed in different order, in the window we see the selection as two non-contiguous pieces.

Also note that characters not present in the font are displayed as hollow rectangles. I.e. I need to install a more complete font!
The Gnome2 text framework mentioned earlier also has excellent internationalization support.
Current releases of Emacs and XEmacs support some internationalization, using the Mule framework which supports text in many character sets. However, current releases of Mule do not yet support Unicode, which is where most of the world is heading. Mule is based on some rather dated design decisions. JEmacs will not support Mule; it won't need to.
Documents will be increasingly represented using XML externally and DOM (Document Object Model) internally. Most of the programs and libraries for manipulating and formatting XML are written in Java. For example, the Apache group has some major Java-based XML projects.
If Emacs is to support word processing features, it should build on XML standards. It is easier to use third-party Java libraries if the Emacs core is Java-based.
Kawa already has extensive built-in XML support, partly to implement XQuery, the XML Query language. Kawa has an integrated framework that combines support for sequences, iterators, and abstract nested trees (like XML). JEmacs is partly integrated with this framework, but not to the extent it could be. For example, if Buffer was made abstract then one could have editable documents which are defined using transformations from other documents (rather like a database view).
A ‘proof-of-concept’ prototype is working, including partial Elisp implementation. There is still a lot of work before you want to use JEmacs for day-to-day general editing.
Using the libraries of Java and Swing takes care of many problems.
JEmacs has a mailing list and a home page.
JEmacs is currently distributed together with Kawa.
I did most of JEmacs development between Match 1999 and June 2000. Since then it has been been a matter of small updates to make JEmacs consistent with the rest of Kawa, with almost no real development, except for the recent effort the split out Swing dependencies. Mnay people have expressed interested in JEmacs, and like the concept. Unfortunately no one has volunteered to help with development, and I have had to concentrate on other projects. Perhaps this article has inspired you to volunteer?
[Bothner97] A Gcc-based Java Implementation. IEEE Compcon '97. 1997.
[Bothner98a] Kawa - Compiling Dynamic Languages to the Java VM. Usenix Annual Technical Conference. 1998.
[Bothner98b] Kawa: Compiling Scheme to Java. Lisp Users Conference. 1998.
[EmacsManual] GNU Emacs Manual. Free Software Foundation. 1985.
[Elisp] GNU Emacs Lisp reference manual. Free Software Foundation. 1990.
[Emacs] EMACS: The Extensible, Customizable, Self-Documenting Display Editor. In Text manipulation: Proceedings of the ACM SIGPLAN/SIGOA symposium (Portland, OR, June, 1981). June, 1981.
[DynamicScope] Down with Emacs Lisp: Dynamic Scope Analysis. In ICFP Proceedings, SIGPLAN Notices, 36(10), pages 38-49. 2001.
[SwingTutorial] The JFC Swing Tutorial: A Guide to Constructing GUIs. Addison-Wesley, ISBN 0-201-43321-4. 1999.