Per's JavaFX blog entries
Read JavaFX-using-Kawa-intro first. That introduces JavaFX and how you can use Kawa to write rich GUI applications.
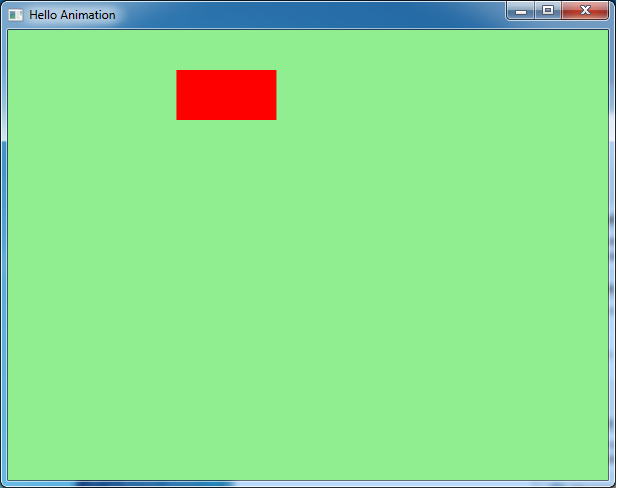
This example demonstrates simple animation: A rectangle that moves
smoothly left to right and back again continuously.
This is example is converted from HelloAnimation.java written in Java by Kevin Rushforth. Here is the entire program HelloAnimation.scm:
(require 'javafx-defs) (javafx-application) (define rect (Rectangle x: 25 y: 40 width: 100 height: 50 fill: Color:RED)) (javafx-scene title: "Hello Animation" width: 600 height: 450 fill: Color:LIGHTGREEN rect) ((Timeline cycle-count: Timeline:INDEFINITE auto-reverse: #t (KeyFrame (Duration:millis 500) (KeyValue (rect:xProperty) 200))):play)
The first two lines are boilerplate, as in JavaFX-using-Kawa-intro.
The (define rect (Rectange ...)) defines a variable
rect, and initializes it to a new Rectangle,
using an object constructor as seen before.
The (javafx-scene ...) operations creates the scene with
the specified title, width, height
and fill (background color) properties.
It adds the rect to the scene, and then creates a window to make it visible.
Finally, we animate rect. This requires some background explanation.
Key values and key frames
To animate a scene you create a TimeLine data structure,
which describes what properties to modify and when to do so.
Once you have done so, call play on the TimeLine,
which instructs JavaFX's animation engine to start running the animation.
In this example, the animation continuous indefinitely:
When done, it reverses (because auto-reverse was set to true)
and starts over.
The timeline is divided into a fixed number of
key frames,
which are associated with a specific point in time.
In the current example there is the implicit starting key-frame
at time 0, and an explicit key-frame at time 500 (milliseconds).
(The KeyFrame specifies a duration or ending time,
where the start time is the ending time of the previous key-frame,
or 0 in the case of the first key-frame.)
The animator (or programmer) specifies various properties (such
as positions and sizes of objects) at each key-frame, and then the
computer smoothly interpolates between the key-frames.
By default the interpolation is linear, but you can specify other
kinds of interpolation.
Each KeyFrame consists of some KeyValue objects.
A KeyValue species which property to modify
and the ending value that the property will have at the end of the key-frame.
In the example, we have a single KeyValue to modify
rect:x, ending at 200. (The start value is 25, as set when
rect was constructed.)
In JavaFX, the properties to animate are specified using
Property objects. Typeically, a property is a reference
to a specific field in a specific object instance. You register the
property with the animation engine (as shown in the sample), and then
the animation engine uses the property to modify the field.
In the example the expression (rect:xProperty)
(equivalent to the Java method call rect.xProperty())
returns a property that references the x property
of the rect object.
The Property object also has ways to register dependencies
(rather like change listeners) so that things get updated
when the property is changed. (For example the rectangle is re-drawn
when its x property changes.)
Here is a static screenshot - obviously an animiated gif would be nicer here!
More information
ToDo: Links to documentation and other JavaFX examples.JavaFX 1.0 was a next-generation GUI/client platform. It had a new Node-based GUI API and used a new language, JavaFX Script, whose goal was to make it easier to program Rich Client applications. (Yours truly was hired by Sun to work on the JavaFX Script compiler.) In 2010 the JavaFX Script language was cancelled: JavaFX would still refer to a new GUI based API based on many of the same concepts, but the primary programming language would be Java, rather than JavaFX Script.
Java is a relatively low-level and clumsy language for writing Rich Client appliations, though it's not too painful. Still, there was a reason we worked on JavaFX Script: It had a number of features to make such programs more convenient. Luckily, other JVM languages - and specifically Kawa-Scheme - can take up the slack. Below I'll show you a simple Hello-World-type example, and then explain how you can try it yourself. In later acticles I'll show different examples.
Simple buttons and events
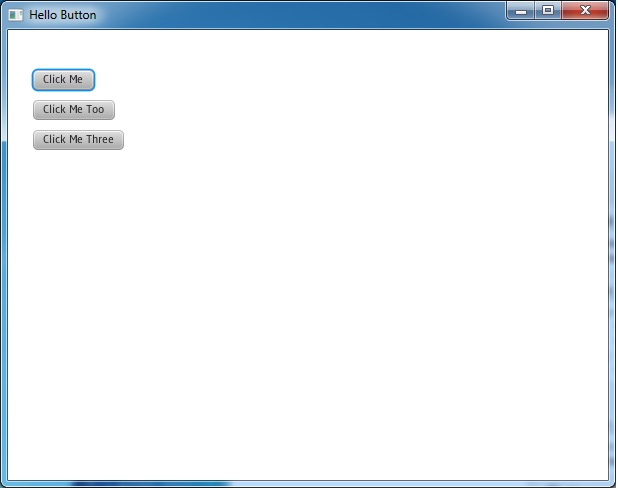
Our first example is just 3 buttons and 2 trivial event handlers. It is translated from HelloButton.java written in Java by Richard Bair.
(require 'javafx-defs) (javafx-application) (javafx-scene title: "Hello Button" width: 600 height: 450 (Button text: "Click Me" layout-x: 25 layout-y: 40 on-action: (lambda (e) (format #t "Event: ~s~%" e)) on-key-released: (lambda (e) (format #t "Event: ~s~%" e))) (Button text: "Click Me Too" layout-x: 25 layout-y: 70) (Button text: "Click Me Three" layout-x: 25 layout-y: 100))
For those new to Scheme, the basic syntactic building block has the form:
(operator argument1 ... argumentN)The
operator can be a function (like format),
an arithmetic operator in prefix form (like (+ 3 4)),
a command, a keyword (like lambda), or a user-defined macro.
This general format makes for a lot of flexibility.
The first two lines in HelloButton.scm are boiler-plate:
The require imports various definitions and aliases,
while the (javafx-application) syntax declares
this module is a JavaFX Application.
The javafx-scene form (a macro) creates a scene,
which is a collection of graphical objects.
The Scene has certain named properties (title,
width, and height), specified using keyword arguments. The Scene also has 3 Button children.
Finally, the make-scene command puts the scene
on the stage (the window) and makes it visible.
Each Button form is an object constructor. For example:
(Button text: "Click Me Three" layout-x: 25 layout-y: 100)is equivalent to the Java code:
javafx.scene.control.Button tmp = new javafx.scene.control.Button();
tmp.setText("Click Me Three");
tmp.setLayoutX(25);
tmp.setLayoutY(100);
return tmp;
The on-action and on-key-released
properties on the first Button bind event handlers.
Each handler is a lambda expression or anonymous function that takes an event e as a parameter. The Kawa compiler converts the handler to a suitable
event handler object using
SAM-conversion features
.
(This conversion depends on the context, so if you don't have a
literal lambda expression you have to do the conversion by hand
using an object operator.)
Getting it to run
Downloading JavaFX 2.x beta
For now JavaFX is only available for Windows, but Mac and GNU/Linux ports are being worked on and mostly work. (I primarily use Fedora Linux.) The primary JavaFX site has lots of information, including a link to the download site. You will need to register, as long the software is beta. Download the zipfile and extract it to some suitable location.
In the following, we assume the variable JAVAFX_HOME
is set to the build you've installed. For example (if using plain Windows):
set JAVAFX_HOME=c:\javafx-sdk2.0-betaThe file
%JAVAFX_HOME%\rt\lib\jfxrt.jar should exist.
Downloading and building Kawa
The JavaFX support in Kawa is new and experimental (and unstable), so for now you will have to get the Kawa source code from SVN.
There are two ways to build Kawa. The easiest is to use Ant - on plain Windows do:
ant -Djavafx.home=%JAVAFX_HOME%or on other platforms (including Cygwin):
ant -Djavafx.home=$JAVAFX_HOME
Alternatively, you can use configure and make
(but note that on Windows you will need to have Cygwin installed to use this approach):
$ KAWA_DIR=path_to_Kawa_sources $ cd $KAWA_DIR $ ./configure --with-javafx=$JAVAFX_HOME $ make
Running the example
On Windows, the easiest way to run the example is to use the
kawa.bat created when building Kawa. It sets up
the necessary paths for you.
%KAWA_HOME%\bin\kawa.bat HelloButton.scm
On Cygwin (or Unix/Linux) you can use the similar kawa.sh.
I suggest setting your PATH to find
kawa.bat or kawa.sh, so you can just do:
kawa HelloButton.scm
Using the kawa command is equivalent to
java -classpath classpath kawa.repl HelloButton.scmbut it sets the classpath automatically. If you do it by hand you need to include
%JAVAFX_HOME%\rt\lib\jfxrt.jar
and %KAWA_DIR%\kawa-version.jar.
This is what pops up:
If you click the first button the action event fires, and
you should see something like:
Event: javafx.event.ActionEvent[source=Button@3a5794[styleClass=button]]
If you type a key (say n) while that button has focus
(e.g. after clicking it),
then when you release the key a key-released event fires:
Event: KeyEvent [source = Button@3a5794[styleClass=button], target = Button@3a5794[styleClass=button], eventType = KEY_RELEASED, consumed = false, character = , text = n, code = N]
Note: Running a JavaFX application from the Kawa read-eval-print-loop (REPL) doesn't work very well at this point, but I'm exploring ideas to make it useful.
Compiling the example
You can compile HelloButton.scm to class files:
kawa --main -C HelloButton.scm
You can execute the resulting application in the usual way:
java -classpath classpath HelloButtonor use the
kawa command:
kawa HelloButton
Next
JavaFX-using-Kawa-animationRead JavaFX-sequence-basics first.
A sequence whose JavaFX type is T[] translates to
the Java generic type Sequence<? extends T>.
A primitive
type like Integer
is mapped to the Java primitive type int.
Unfortunately, the JVM doesn't support generics with
primitive type parameters such as Sequence<int>;
instead we have to use Sequence<java.lang.Integer>.
An ArraySequence would be implemented using an array of
java.lang.Integer instances, which are much more expensive
than a Java int array: java.lang.Integer
requires memory allocation, which takes more time and memory.
Before you can do arithmetic the java.lang.Integer
has to be converted to an int.
Converting an int to a java.lang.Integer
(typically using Integer.valueOf(int))
is called boxing, because you create a box
(the
Integer object) to hold the value.
Converting a java.lang.Integer to an int
(typically using Integer#intValue()) is called unboxing.
As boxing is quite expensive, we'd like to find a way to use sequences of primitive unboxed values directly.
Abandoned approach: IntegerSequence
One approach is to define a new interface for each primitive type:
public interface IntegerSequence extends Sequence<java.lang.Integer> {
int getAsInt(int position);
void toArray(int sourceOffset, int length, int[] array, int destOffset);
}
Then the compiler would translate Node[] to Sequence<Node>, while Integer[] would be translated
to IntegerSequence.
We'd create similar XxxSequence interfaces for each
unboxed type Xxx.
Likewise for XxxAbstractSequence,
XxxArraySquence, and so on.
Generating these classes can be done conveniently with a
template processor.
Because a Sequence<Integer> doesn't implement
IntegerSequence,
every sequence class that depends on a type parameter T
would need to be replicated for each primitive type.
While there aren't very many Sequence
interfaces and classes, it's still somewhat costly in terms of static
footprint.
Naively, the sequence-variable classes also have to be multiplied,
but it is possible to be smarter. For example, we could parameterize
the SequenceVariable class in terms of both the element
type and the sequence type:
class SequenceVariable<T, TSEQ extends Sequence<T>> {
/** Get current value, as a Sequence. */
public TSEQ get() { ... }
...
}
An Integer[] variable would be compiled to a
Sequencevariable<Integer,IntegerSequence>.
However, this was getting complicated, plus it entailed a lot of
code-duplication so I set this approach aside.
Direct unboxed support in Sequence
Instead, I added support for the primitive types
directly in Sequence:
public interface Sequence<T> {
public T get(int position);
... other methods as before ...;
byte getAsByte(int position);
short getAsShort(int position);
int getAsInt(int position);
... etc ...;
}
Similarly for AbstractSequence,
which provides default implementations in terms of get:
public class AbstractSequence<T> implements Sequence<T> {
public int getAsInt(int position) {
return ((Number) get(position)).intValue();
}
... etc ..;
}
We do need separate ArraySequence sub-classes
for each primitive type. (The following is simplified in
that it ignores the buffer-gap.)
class abstract ArraySequence<T> extends AbstractSequence<T> {
protected abstract T getRawArrayElementAsObject(int index);
public T get(int position)
if (position < 0 || position >= array.length)
return getDefaultValue();
return getRawArrayElementAsObject(position);
}
}
class ObjectArraySequence<T> extends ArraySequence<T> {
T[] array;
protected abstract T getRawArrayElementAsObject(int index) {
return array[index];
}
}
class IntegerArraySequence extends ArraySequence<java.lang.Integer>
int[] array;
protected Integer getRawArrayElementAsObject(int index) {
return Integer.valueOf(array[index]);
}
public int getAsInt(int position) {
if (position < 0 || position >= array.length)
return 0;
else
return array[position];
}
}
This works pretty well. The compiler translates:
def x : Integer[] = ...; x[i]
to
SequenceVariable<java.lang.Integer> x = ....; x.get().getAsInt(i)
Then if the value in x is an IntegerArraySequence
then we end up calling IntegerArraySequence#getAsInt,
which does no boxing or unboxing.
Note it is possible the sequence value at run-time is an
ObjectArraySequence<Integer> rather than
an IntegerArraySequence. That could happen in
the case of bind forms, or other expressions which
have not (yet) been optimized to avoid boxing.
The right thing still happens in those cases,
though with the boxing overhead.
Various methods in SequenceVariable also needed to be
replicated for each primitive type.
The presence of an on-replace trigger
complicates JavaFX sequence updating.
Specifically, it makes it difficult to implement copy-on-assignment
or copy-when-shared
efficiently.
In JavaFX a trigger is a kind of function that gets called
after an update. It has up to
four (optional) parameters: The old value of the sequence
variable, the start and end position of the replaced slice
(relative to the old value), and the new
elements that replaced the slice.
However, when we modify an ArraySequence in-place,
the old value doesn't exist: We'd have to make a copy before
we do the modification, which negates the whole point of
in-place modification. Likewise, on a single-element
insert or replace we don't have the new elements as a
separate sequence value.
What saves us is that most of the time a trigger doesn't actually use the old-value or the new-elements, except perhaps to read a single item. So we can design an internal API where we don't create these as separate sequence values unless we have to. The idea is that a trigger gets compiled to a method with the following interface:
public abstract void onChange(ArraySequence buffer,
Sequence oldValue,
int startPos, int endPos /* exclusive*/,
Sequence newElements);
The trick is that one or both of oldValue and newElements may be null. In that case buffer must be non-null, and there is an algorithm (to be described) for extracting oldValue and newElements from the buffer, if needed.
First, the trivial case when we replace the sequence wholesale:
v = newElements
In that case we save the oldValue before doing the update, and
pass buffer=null, startPos=0,
and endPos=oldValue.size().
Next consider the case when the oldValue is an unshared
ArraySequence.
This is the case we want to optimize - we want to modify it in-place,
and avoid creating a new object unnecessary. The trick is to store the
deleted/replaced elements in the gap of the ArraySequence.
Specifically, for:
seq[loIndex..<hiIndex] = newElements
the algorithm is:
- If the available space (i.e., size of the gap) is less than the
number of new elements, allocate a larger buffer (maybe twice the
size of the old buffer), and copy the elements, leaving the gap at
index
loIndex. - Otherwise, adjust the gap if necessary to start at
loIndex. - Insert
newElementsat the start of gap. Adjust the start of the gap to follow the inserted elements, and the end of the gap to be after the deleted elements. Note at this point the deleted/replaced elements are at the end of the gap, as in this diagram:+-------------------------+ 0 | Preserved elements | +-------------------------+ loIndex | Newly-inserted elements | +-------------------------+ gapStart | Unused (gap) | +-------------------------+ gapEnd-hiIndex+loIndex | Newly-deleted elements | +-------------------------+ gapEnd | Preserved elements | +-------------------------+ buffer.length
[Layout of an
ArraySequencebuffer just after an update, while the triggers are running.] - Invoke the triggers, passing the
ArraySequenceas thebuffer.oldValueis null. IfnewElementsexists as a Sequence object, pass that; if we're inserting or replacing a single item we don't havenewElements, so passnewElements=null. - If the buffer is an object type, null out the elements in the gap corresponding to the deleted elements (to avoid memory leaks).
If the old value is not an ArraySequence, or it is a shared
ArraySequence, first copy the old value into a fresh
unshared ArraySequence, and proceed as above, except for oldValue
we can pass the old value instead of null.
(The rationale for this algorithm (and specifically that we insert at
the start of the gap) is that it is well-behaved for updates in a
forwards
direction: After an update that replaces the range [i..<j]
by n elements the start of the gap will be at (i+n). It is likely that
the next operation will be replace a range starting at (i+n) - that is
certainly the case for an algorithm that replaces the elements in
sequential order (when n==1 for each iteration). So that gap will be
correctly positioned in that very common case.)
(A possible concern is that requiring the buffer to have room for both deleted and inserted elements might mean that we have to re-allocate the buffer just to remember the deleted elements for the triggers, and then have excess space after running the triggers. But this isn't an issue for plain deletion or insertion, only replacement, and the most common replacement is a single element, so the extra space needed is just enough for one element.)
Compile-time
First we assume a simple non-optimized implementation:
Compile:
var v : T[] on replace oldV[i..j] = newV { triggerBody }
to (mix of Java and JavaFX pseudo-code):
new SequenceChangeListener() {
public void onChange(ArraySequence $buffer,
Sequence $oldValue,
int i, int $j,
Sequence $newElements) {
def j = $j-1;
def oldV = Sequences.getOldValue($buffer, $oldValue, i, $j);
def newV = Sequences.getNewElements($buffer, i, $newElements);
triggerBody;
}
The library method Sequences.getOldValue
tests if the $oldValue argument is null,
in which case it creates a fresh sequence value
by copying the old values from the buffer gap of the $buffer.
The library method Sequences.getNewElements
similarly handles the case when $newElements is null.
Of course the whole point is to only do the copying
if the application actually needs these values.
So the first obvious optimization: If the trigger
doesn't reference oldV or newV
then we don't need to call Sequences.getOldValue or
Sequences.getNewElements, respectively.
We can do even better: Most triggers only use newV
in the context of indexing newV[i], or
sizeof newV or for (x in newV) {...}.
In that case we don't need to call Sequences.getNewElements.
For example instead of newV[i], we extract (ignoring bounds-checking):
buffer.array[loIndex + i]See
Sequences.st for the actual code.
More generally, the compiler makes the following mappings:
oldV[j] => Sequences.extractOldElement($buffer, $oldValue, i, $j, k) sizeof oldV => Sequences.extractOldSize($buffer, $oldValue, $j) newV[k] => Sequences.extractOldElement($buffer, i, $newElements, k) sizeof newV => Sequences.extractNewSize($buffer, i, $newElements)
Sequences in JavaFX are powerful, but it is difficult to implement them efficiently. The basic problem is illustrated by this:
var x = [....]; var y = x; x[i] = a; // y[i] must not be modified.
Note the distinction between an immutable sequence value
,
vs a sequence variable
,
which is a named location which can contain different
sequence values at different times.
We will distinguish between (plain) assignment to a
sequence variable:
y = x;
versus modification of a sequence variable, which modfies the old value in some way, either by indexed assignment, inserting new elements, or deleting old elements.
So let's look at various ways to implement the desired semantics.
The copy-on-assignment approach
This is fairly simple. A sequence is implemented on top of an array.
When we assign the sequence to another variable (as in the
initialization of y from x above)
we copy the entire sequence including the underlying array.
Then the modification of x is implemented
by modifying x's underlying array, without
bothering y. Sequence indexing is fast for both
read and write. What becomes expensive is sequence assignment,
which includes initialization of sequence variables,
and passing of sequence parameters. The latter might be mitigated
if we're sure the argument isn't modified during the function,
as is normally the case, but that becomes tricky to verify.
The copy-on-shared-write solution proposed later can be thought
of as delaying the copying until needed: Instead of actually
copying the sequence, we set a shared
bit to force copying
if there is a subsequence modification.
The copy-on-modification approach
Another solution is to translate:
x[i] = a;to:
x = [x[0 ..< i], a, x[i+1 ..]];
I.e. we implement modification by creating a new sequence with all the original elements plus the one modification. This is simple, correct, and has fast read performance, but even a single-item modification requires copying the entire sequence.
The delta-chain approach
Rather than creating a modified x we can create a "delta":
x = new ElementReplacementSequence(x, i, a);where
ElementReplacementSequence is:
class ElementReplacementSequence<T> extends AbstractSequence<T> {
Sequence<T> original;
int replacementIndex;
T replacementValue;
public ElementReplacementSequence(Sequence<T> original, int replacementIndex, T replacementValue) {
this.original = original;
this.replacementIndex = replacementIndex;
this.replacementValue = replacementValue;
}
public T get(int i) {
return i == replacementIndex ? replacementValue
: original.get(i);
}
public int size() { return original.size(); }
}
This approach was used initially in JavaFX, and had the
advantage of simplicity, correctness, and moderately fast write performance.
(You do have to allocate a new
ElementReplacementSequence each time.)
It's appealing because we never modify a sequence, only
sequence variables. Thus both the old and new value are directly
accessible, which makes triggers nice and easy.
However, naively implemented it has horrible read performance:
After 1000 replacements, x will be a chain
of a 1000 ElementReplacementSequence objects
which has to be searched linearly.
Michael Heinrichs and Brian Goetz implemented various heuristics to come up with a hybrid of delta-list and eager copying: When the delta-list becomes too long or the sequence is short anyway just copy it. This has worked reasonably well in practice, but it's pretty ad hoc, and we're still doing quite a bit more work on both reads and writes compared to indexing into an array.
Persistent arrays
The logical extension of the delta-chain approach
is to use a persistent array
(see
Wikipedia
for some links). This would have the nice properties of
the delta-chain appraoach, but using algorithms and
data structures with guaranteed performance bounds:
either O(1) or at worst O(log(N)), which is presumably tolerable.
An issue with persistent arrays is that the desired performance guarantees require some non-trivial data structure and algorithms, but that is compensated by simplicity elsewhere. A bigger problem is that overhead and constant factors are likely to be significant. I'm guessing that the storage needed would at least be double that of a plain array (consider the extra pointers and flags needed for most balanced-tree implementations); memory locality would be much worse; and tree walking and management would be markedly slower than array indexing.
The copy-when-shared solution
We can optimize the copy-on-modification approach: If the sequence value is represented using an array and there is no other reference to the sequence, then we can just modify the array in place. How do we check that there is no other reference to the sequence? The classical method is to use a reference count. However, maintaining an accurate reference count is expensive, especially if it's not doing double-duty for memory managment. However, we don't need accuracy: If we know there is exactly one reference, then we can modify the underlying array in-place; otherwise (including when we're not sure) we copy, to be safe. Likewise, if the old value is not anArraySequence
(for example it might be a IntRangeSequence),
then modifying in-place doesn't make sense, so we first
copy the old value into a fresh unshared ArraySequence
before doing the modification.
Even a single-bit reference count works pretty well:
We set that bit (the shared
bit) whenever sharing is introduced.
The original algorithm was to set the shared bit whenever we access
(read) a sequence in a way that could cause sharing.
Reading a single item or the size of a sequence does not cause sharing,
so we don't set the shared bit in those cases.
Using a single bit causes performance loss in some cases:
var x = [ ... ]; ... some modifications to x ....; some_function(x); ... more modifications to x ....; another_function(x);
When some_function is called, we cause
the current value of x to be shared. Thus any
more modifications
will force a copy. But almost always
the sharing in some_function is temporary and harmless, as the
function does not does not modify x.
However, it's difficult to statically verify this.
One way to solve this is to use a multi-bit reference count,
and make sure we decrement the count. The plan is to add
this in the future. (It is partially implemented.)
Buffer-gap arrays
Replacing a sequence element in-place
is easy to implement
by just modifying an element in the underlying array.
Insertions and deletions may require more work, including
copying elements and allocating a new bigger array.
If insertions and deletions are infrequent, or tend to
cluster or be sequential then it works pretty well to use
a gap buffer
as used by Emacs
and Swing's GapVector.
This data structure has low memory overhead (basically just the
gap), fast read access, and good memory locality:
There is no pointer-chasing
as in balanced-tree or linked-list data structures.
Modifications that are sequential or clustered around the same position
are also fast, since we don't need to move the gap
much. For example, building a sequence by incrementally
appending new elements is fast, as is replacing all the elements in order.
Modifications that jump around
in the sequence
can be expensive, because you have to move the gap
to the position of the modification. This means copying
elements between the current gap position to the
position of the modification.
The hope is programs that do this are relatively rare,
and the slowness of this case is more than made up for
other common cases being fast.
Note that single-element writes are fast, but only if there are no triggers or other dependencies. See this article for how triggers are implemented.
This article introduces the core classes used for
the JavaFX sequence implementation.
Note that these are internal classes and interfaces,
not a supported API.
This is purely for your information and edification:
The goal is to help you get a mental model of what is under the hood
,
and the approximate cost of the various sequence operations.
The Sequence interface
A JavaFX sequence type T[] is implemented
using classes that implement the Sequence<T> interface:
public interface Sequence<T> {
/** Number of items in sequence. */
public int size();
public T get(int position);
/** Copy elements from sequence into an array. */
public void toArray(int sourceOffset, int length, Object[] array, int destOffset);
/** Get this[startPos..<endPos]. */
public Sequence<T> getSlice(int startPos, int endPos);
/** What to return when an index is out-of-range. */
T getDefaultValue();
... a few more ...;
}
All (existing) Sequence concrete classes extend
AbstractSequence, which implements various utility methods:
public class AbstractSequence<T> implements Sequence<T> {
... default implementations of some methods ...
}
(Idea to consider: We might want to merge Sequence and
AbstractSequence. That would save a little bit of static
footprint. It should also slightly improve performance, since
virtual method calls are usually more efficient than interface
method calls, especially on not-so-smart VMs.)
The default
sequence implementation
is ArraySequence, which (surprise!) uses a Java array.
The following is highly simplified;
we'll go into ArraySequence in more detail in a later note.
public class ArraySequence<T> extends AbstractSequence<T> {
T[] array;
// Warning - this is simplified!
public T get(int position) {
if (position < 0 || position >= array.length)
return getDefaultValue();
return array[position];
}
...
}
There are a few special Sequence classes.
SingletonSequence is an optimization for single-item
sequences. IntRangeSequence (and the similar
NumberRangeSequence) are used to implement
[start..<end] ranges:
public class IntRangeSequence extends AbstractSequence<Integer> {
int start, step, size;
...;
public Integer get(int position) {
if (position < 0 || position >= size)
return getDefaultValue();
else
return (start + position * step);
}
}
Finally, SubSequence is used for sequence slices:
public class SubSequence<Integer> extends AbstractSequence<Integer> {
public T get(int position) {
if (position < 0 || position >= size)
return getDefaultValue();
else
return sequence.get(startPos + step * position);
}
...
}
The JavaFX type T[] is actually mapped to the
Java type Sequence<? extends T>,
where the
specifies a wildcard.
This is to support
co-variance of sequence types. You see this below.
? extends T
What about sequences of primitive
types, such as Integer,
which corresponds to the Java int type?
That deserves a separate article.
A named mutable variable is represented by SequenceVariable.
It stores the current value
,
which is a sequence value, of type Sequence<? extends T>.
class SequenceVariable<T> {
protected Sequence<? extends T> $value;
public Sequence<? extends T> getAsSequence() { return $value; }
public Sequence<? extends T> setAsSequence (Sequence newValue) {
$value = newValue;
... handle triggers and dependencies ...
}
public void insertBefore(T value, int position) {
replaceSlice(position, position, value);
}
public void replaceSlice(int startPos, int endPos, T newValue) {
... interesting stuff ...
}
public void replaceSlice(int startPos, int endPos, Sequence newValue) {
... interesting stuff ...
}
...
}
All of the sequence insert/delete/replace operations map down to either
replaceSlice(int startPos, int endPos, T newValue)
or replaceSlice(int startPos, int endPos, Sequence<? extends T> newValues), where the former can be viewed as optimizations of the latter.
These operations for updating sequence variables are interesting and tricky enough that they deserve separate articles JavaFX-sequence-updating and JavaFX-sequence-triggers.
The new read-eval-print-loop (REPL) for JavaFX
required some major changes in the scripting
API
for JavaFX.
JavaFX had for a while supported the javax.script API
specified by JSR-223.
However, that JavaFX implementation didn't allow you to declare a variable in
one "eval" and make it visible in future commands, which made it
rather useless for a REPL.
This turns out to be somewhat tricky for a
compiled language with static name binding and typing.
Unfortunately, JSR-223 has some fundamental design
limitations in that respect.
(Embarrassingly, I was a not-very-active member of the JSR-223 expert group.
It would have been better if we could have thought a little more about
scripting staticly-typed languages, but we didn't have time.)
Design limitations in javax.script
Top-level name-to-value bindings in JSR-223 are
stored in a javax.script.Bindings instance, which is
basically a Map. Unfortunately, Bindings is a
concrete class that the programmer can directly instantiate
and add bindings to, and there is no way to synchronize
a Bindings instance with the internal evaluator state.
(Note that top-level bindings have to be maintained in a language-dependent
data structure if the language supports static typing, since typing
is language-dependent.) This means the script engine has to
explicitly copy every binding from the Bindings object
to the language evaluator - or the script evaluator has to be
modified to search the Bindings. Worse, if a script
modifies or declares a binding, that has to be copied back to
the Bindings, which is an even bigger pain.
This problem could have been avoided
if Bindings were an abstract class to be implemented
by the language script engine.
An alternative solution could allow the evaluator to register
itself as as listener
on the Bindings object.
JSR-223 does support compilation being separate from evaluation. Unfortunately, it assumes that name-to-value bindings are needed during evaluation but not during compilation. This is problematic in a language with lexical binding, and fails utterly in a language with static typing: The types of bindings have to be available at compile-time, not just run-time.
The Invocable interface is also problematical.
It invokes a function or method in a ScriptEngine,
without passing in a ScriptContext, even though
invoking a function is basically evaluation, which should require
a ScriptContext.
The ScriptContext interface has an extra
complication in that it consists of two Bindings objects,
of which the global
one seems to have limited utility.
Making it worse is that some methods use
the default ScriptContext of a ScriptEngine
and some take an explicit ScriptContext parameter.
The new JavaFX scripting API
Because of these problems with javax.script,
I implemented a new JavaFX-specific API.
These classes are currently in the com.sun.tools.javafx.script
package; after some shaking down
they might be moved to
some other package, perhaps javafx.script.
The class JavaFXScriptCompiler manages the compilation
context
, including the typed bindings preserved between
compilations, and a MemoryFileManager pseudo-filesystem
that saves the bytecode of previously compiled commands.
The main method of JavaFXScriptCompiler is compile.
This takes a script, compiles it, and (assuming no errors) returns
a JavaFXCompiledScript.
The main method of JavaFXCompiledScript is eval,
which takes a JavaFXScriptContext, evaluates the script,
and returns the result value.
The JavaFXScriptContext contains the evaluation state,
which is primarily a ClassLoader. Creating a JavaFXScriptContext
automatically creates a JavaFXScriptCompiler, so in the
current implementation there is a one-to-one relationship between
JavaFXScriptContext and JavaFXScriptCompiler.
(In the future we might allow multiple JavaFXScriptContext
instances to share a single JavaFXScriptCompiler.)
This API is very much subject to change.
The REPL API
The actual REPL is provided by the ScriptShell class,
which is implemented using the above API. It first reads in commands
from the command line (the -e option), or a named
file (the -f option). It then enters the classic
REPL loop: Print a prompt, read a line, evaluate it, and
print the result.
Most of these behaviors can be customized by overriding
a method. For example when the compiler finds an error it creates a
Diagnostic object, which is passed to a report method.
The default handling
is to print the Diagnostic, but a sub-class of
ScriptShell could override report to do
something else with the Diagnostic.
The ScriptShell API is also very much subject to change
as we get more experience with it.
The new javax.script wrapper
The class JavaFXScriptEngineImpl is the JavaFX implementation
of the standard javax.script.AbstractScriptEngine class.
It was re-written to be a wrapper on top of the API discussed earlier.
Because of the previously-mentioned limitations of javax.script
it is not completely faithful implementation of JSR-223.
It uses a WeakHashMap to translate from the
Bindings used by the javax.script API
into the JavaFXScriptContext objects used by the
internal API. Compilation and evaluation of a script need to use
JavaFXScriptContext consistently.
This means there are basically two usage modes that should work:
-
It is best to always use the default
ScriptContextas returned by theScriptEngine'sgetContextmethod. Don't callcreateBindings,getBindings,setBindings, orsetContext. -
If you really need to use any of the above four methods, don't
try to use either of the
compilemethods. The reason for this is that compilation does need to use the script context, and it should be the same as used for evaluation.
A read-eval-print-loop is a well-known feature of many language implementations, but isn't that common with compiled languages, especially ones that have static typing and lexical name lookup.
See this companion article on the scripting API and implementation issues.
The class com.sun.tools.javafx.script.ScriptShell implements the
actual repl. It is an application that was based on
the language-independent jrunscript command.
but you can also subclass it if you want to customize it.
To run the REPL, start the ScriptShell application - for example:
$ CLASSPATH=/tmp:dist/lib/shared/javafxc.jar \ java com.sun.tools.javafx.script.ScriptShell
Then you type commands at it:
/*fx1*/ var xy = 12 12 /*fx2*/ xy+10 12The prompt has the form of a comment, to make it easier to cut-and-paste. The name inside the comments is used as the name of a "scriptlet" which shows up in error messages and exceptions.
You can define functions, modify variables, and call functions:
/*fx3*/ function xy_plus (n:Integer):Integer { xy + n }
/*fx4*/ ++xy
13
/*fx5*/ xy_plus(100)
113
You get warnings:
/*fx6*/ xy=2.5 fx6:1: possible loss of precision found : Number required: Integer 2
and errors:
/*fx7*/ xy="str" fx7:1: incompatible types found : String required: Integer
and exceptions:
/*fx8*/ xy/0
java.lang.reflect.InvocationTargetException
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:616)
at com.sun.tools.javafx.script.JavaFXCompiledScript.eval(JavaFXCompiledScript.java:59)
at com.sun.tools.javafx.script.ScriptShell.evaluate(ScriptShell.java:350)
at com.sun.tools.javafx.script.ScriptShell.evaluateString(ScriptShell.java:311)
at com.sun.tools.javafx.script.ScriptShell.processSource(ScriptShell.java:244)
at com.sun.tools.javafx.script.ScriptShell$1.run(ScriptShell.java:177)
at com.sun.tools.javafx.script.ScriptShell.main(ScriptShell.java:51)
Caused by: java.lang.ArithmeticException: / by zero
at fx8.javafx$run$(fx8]:1)
... 10 more
Each command
is single line. In the future I hope we'll be able to
tell when a command is incomplete
, so the reader can keep reading
more lines until it has a complete command.
Re-definition
You can redefine variables (and functions and classes), but previously-compiled references refer to the earlier definition:/*fx9*/ var xy:String="str" str /*fx10*/ xy str /*fx11*/ xy_plus(100) 102
Now this is correct
in terms of static name-binding,
but perhaps not the most useful. What you probably want
is for xy_plus to use the new definition of xy.
This is what would happen in a typical dynamic language with
dynamic typing and dynamic name-lookup, but with
of compilation and static name-lookup xy_plus uses the
the defintion seen when it was compiled.
Fixing
this would involve some combination of automatic
re-compilation (if xy_plus depends on xy,
and xy is redefined, then re-compile xy_plus),
and extra indirection.
A related issue is that forward references aren't allowed, which means you can't declare mutually dependent functions or classes - unless you type them all in the same command - i.e. on one line! Automatic recompilation could alleviate this: When a command is compiled, we not only remember the declarations it depends on, but also any missing symbols, so we can re-compile it if those later get declared.
Memory and start-up issues
Be aware that executing the first command causes a
noticable pause. While I haven't profiled this, I'm guessing
it is just because we need to load most of javafxc (which
includes most of (a hacked-up version of) javac), and that takes
some time. Subsequent commands run much faster.
Right now we don't do any smart reclaiming of classes. Each command compiles into one or more classes, which are kept around because they may be needed for future commands. Also, the bytecode array of a command is also kept around, since it may be needed when compiling future commands. Hopefully in the future we'll be more clever, so we can get-rid of no-longer-useful classes.