Per's Kawa blog entries
[ 2 * x | x <- [2,3,5,7,11]]The part after the
|is the scan specifier
x <- [2,3,5,7,11], where the scan variable
x ranges over the
elements of the scan sequence [2,3,5,7,11].
The result expression 2 * x is
evaluated for each element of the resulting sequence,
using the scan variables from the scan specifier(s).
Kawa's new (and experimental) List Comprehension Patterns
separate these two parts by making the scan specifier part of
the more general pattern-matching feature.
The result expression can be widely separated from the scan specifier,
as long is it within the lexical scope of any scan variable it uses.
For example they can be in separate REPL commands
(the #|kawa:N# is the REPL prompt).
First, some simple variable definions, using the Kawa-specific
(which is like !define extended to patterns):
#|kawa:1|# (! A [2 3 5 7 11]) #|kawa:2|# (! [A0 A1 A2 A3 A4] A)The first line binds the variable
A to the result
of evaluating the sequence literal
[2 3 5 7 11].
The second illustrates matching
the pattern [A0 A1 A2 A3 A4] against
the value of A, which causes A0...A4
to be matched against corresponding elements of A:
#|kawa:3|# (+ A1 A4) 14Finally, here is a list comprehension (or scan) pattern:
#|kawa:4|# (! [a ...] A)This declares
a to be a scan variable
that ranges over the elements of the scan sequence A.
You can only use a scan variable inside a scan context:
#|kawa:5|# a /dev/stdin:2:1: using scan variable a while not in scan contextA
scan contextis an expression that is followed by ellipsis. The expression is evaluated once for each value of the corresponding scan variable(s), and the result sequence is
splicedinto its context. Here the scan context is the expression
(* 2 a),
which doubles the corresponding element a:
#|kawa:6|# [(* 2 a) ...] [4 6 10 14 22]
This use of ellipsis is inspired by the syntax-rules
macro transformers of Scheme.
A scan variable can be used multiple times in the same scan context (ellipsis expression):
#|kawa:7|# [a ... a ...] [2 3 5 7 11 2 3 5 7 11] #|kawa:8|# [(* a a) ...] [4 9 25 49 121]Ellipses expressions are useful not just in sequence literals, but in the argument list of a procedure call, where the resulting sequence is spliced into the argument list. This is especially useful for functions that take a variable number of arguments, because that enables a convenient way to do fold/accumulate/reduce operations. For example:
#|kawa:9|# (+ a ...) 28because 28 is the result of
(+ 2 3 5 7 11).
An elegant way to implement dot product:
(define (dot-product [x ...] [y ...]) (+ (* x y) ...))When an ellipse expression references two or more distinct scan variables then they are scanned
in parallel. That does not (necessarily) imply muliple threads, but that the first element of the scan result is evaluated using the first element of all the scan sequences, the second element of the result uses the second element of all the scan sequences, and so on.
Sub-patterns in ellipsis patterns
The form before ... in a pattern is itself a (sub-)pattern.
For example, the sub-pattern may include a type specifier,
which applies to each element:
#|kawa:11|# (define (isum [x::integer ...]) (+ x ...)) #|kawa:12|# (isum [4 5 6]) 15 #|kawa:12|# (isum [4 5.1 6]) Argument #1 (null) to 'isum' has wrong type at gnu.mapping.CallContext.matchError(CallContext.java:189) at atInteractiveLevel-6.isum$check(stdin:11) ...(The stack trace line number
stdin:11 is that of
the isum definition.)
You can nest ellipsis patterns, allowing matching against sequences whose elements are sequences.
#|kawa:31|# (define (fun2 [[x ...] ...] [y ...]) #|.....32|# [[(+ x y) ...] ...]) #|kawa:33|# (fun2 [[1 2 3] [10 11 12]] [100 200]) [[101 102 103] [210 211 212]]
Note that x is double-nested, while y is singly-nested.
The following does not work at time of writing, but will soon:
(! [[x y] ...] sequence-of-pairs) ;;Not yet working
Filtering the scan sequence
Often you only want to use some of the elements from the scan sequence.
For example SQL's select has a where with a
boolean expression; only elements for which the expession is true are included.
With scan patterns we have the option to filter the values either where the
scan variables are introduced (the pattern), or when they are used.
(The examples in this section are not working - and the design is undecided.)
Kawa has a splice operator @expr
that takes a sequence and spreads it out to multiple arguuments.
(It is similar to JavaScripts's spread syntax ...expr.)
It is useful to allow splice operators in scan expressions,
and even more useful to allow them in one or more branches of an if.
The following expressions selects the odd elements from a,
doubling them, but drops even elements.
It does the latter by returning a 0-length splice for each even element:
[(if (odd? a) (* 2 a) @[]) ...]
Some reasonable syntatic sugar would be to allow leaving out
the else
expression of an if, having it default
to a zero-length splice:
[(if (odd? a) (* 2 a)) ...]
APL has an expand
operator that repeats elements of an array
based on another count array.
This functionality can be achived using splices in scan expressions.
For example, the following repeats each odd element, and skips even elements:
[(if (odd? a) @[a a] @[]) ...]Equivalently (parsing issues aside):
[@(if (odd? a) [a a] []) ...]
It is also useful to filter at the pattern level.
The following hypothetical syntax would create a scan variable a
from those elements of the scan sequence A that
satisfy the boolean expression (P a).
(! [a ...] A #!if (P a)) ;; hypotheticalNote the sequence of
a values used to evaluate (P a)
would be different than the values in scan expressions.
That might be an issue.
Outer product
Instead of processing multiple sequences in parallel,
sometimes you want the multiplicative
combination of elements
from all the sequences.
This is called Cartesian product (or outer product in APL),
or an cross join in database query languages.
This could be handled with a (not implemented) outer-product function:
(outer-product [10 20] [1 2 3]) ⇒ [[10 1] [10 2] [10 3] [20 1] [20 2] [20 3] [30 1] [30 2] [30 3]]We could use it like this:
(! [[x y] ...) (outer-product X Y))
The above syntax is a bit awkward. Some syntatic sugar would help. If so, it should include an option for filtering only the desired combinations based on a boolean expression.
Comprehension as looping
Scan expression can form the basis of a looping framework
in a programming language.
Assume a function ignore that
ignores its arguments.
Then this is one way to write a
loop,
using its scan expression for its side effects:
for
(let (([i ...] [0 <: 10])) (ignore (do-something-with i) ...))The scan valuable
i range of the
range expression
[0 <: 10].
The scan expression (do-something-with i) is evaluated
for each i.
A general looping construct needs a way to exit the loop
based on a condition, as in a while loop.
Than can be done by having a scan expression return
a special #!done value.
This assumes the scan elements are evaluated sequentially, which is a reasonable default. It would be useful to have some way to request that evaluation be done in parallel. This could be implemented by translating the code to use Java 8 streams, though for performance reasons we only want to do that when parallel execution is wanted.
Implementation notes
A scan variable is implemented as either a java.util.List or a (Java) array.
Using an array may be more efficient, partly because it easier to avoid boxing;
on the other hand it may require more copying..
Scan patterns are expanded by the compiler to a loop which initializes
the array. Scan expressions expand to map calls,
which are generally inlined to loops.
Numerous optimizations and performance improvements are possible.
The DomTerm terminal emulator has a number of unique features. In this article we will explore how it enables dynamic re-flow for Lisp-style pretty-printing.
The goal of pretty-printing is to split a text into lines with appropriate indentation, in a way that conforms to the logical structure of the text.
For example if we need to print the following list:
((alpha-1 alpha-2 alpha-3) (beta-1 beta-2 beta-3 beta-4))in a window 40 characters wide, we want:
((alpha-1 alpha-2 alpha-3) (beta-1 beta-2 beta-3 beta-4))but not:
((alpha-1 alpha-2 alpha-3) (beta-1 beta-2 beta-3 beta-4))
Pretty-printing is common in Lisp environments to display complicated nested data structures. Traditionally, it is done by the programming-language runtime, based on a given line width. However, the line width of a console can change if the user resizes the window or changes font size. In that case, previously-emitted pretty-printed lines will quickly become ugly: If the line-width decreases, the breaks will be all wrong and the text hard to read; if the line-width increases we may be using more lines than necessary.
Modern terminal emulators do dumb
line-breaking: Splitting a long
lines into screen lines, but regardless of structure or even word boundaries.
Some emulators remember for each line whether an overflow happened, or
whether a hard
newline was printed.
Some terminal emulators (for example Gnome Terminal) will use this
to re-do the splitting when a window is re-sized.
However, that does not help with pretty-printer output.
Until now.
Below is a screenshot from Kawa running in DomTerm at 80 colutions.
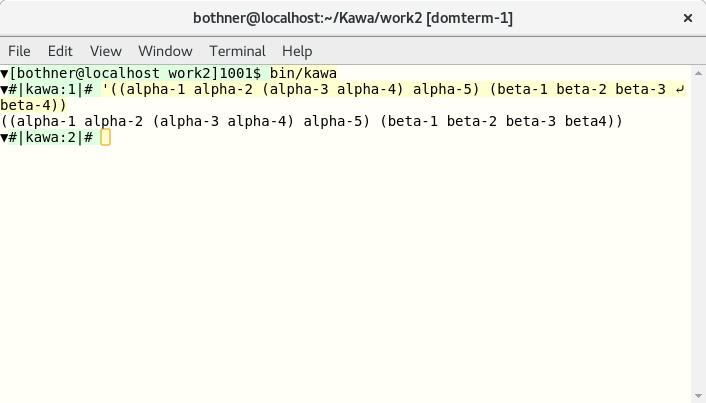
We reduce the window size to 50 columns.
The user input (yellow background) is raw text, so its line is split non-pretty
,
but the output (white background) gets pretty
re-splitting.
(Note the window size indicator in the lower-right.)
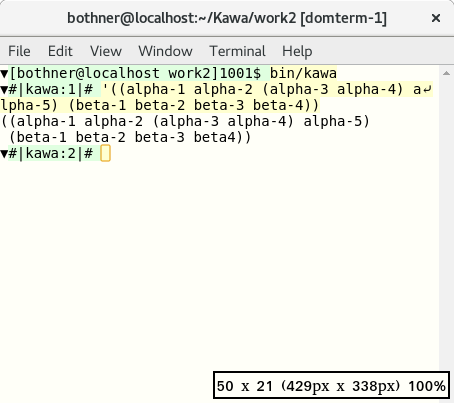
We reduce the window size to 35 columns:
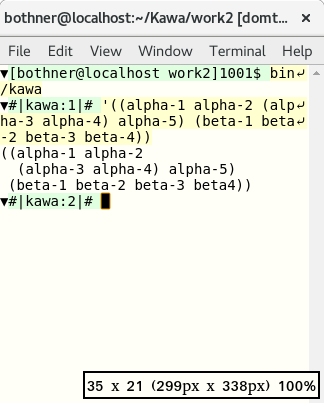
It also works with saved pages
DomTerm allows you to save the current session as
a static HTML page.
If the needed DomTerm CSS and JavaScript files are provided
in the hlib directory, then dynamic line-breaking
happens even for saved log
files.
(The lazy way is to create hlib as a symbolic link
to the hlib directory of the DomTerm distribution.)
Try it yourself on a saved session.
The --debug-print-expr flag causes Kawa to print out each command
before it is compiled and evaluated. The result (shown in red because it
is sent to the standard error stream) is pretty-printed dynamically.
Structured text
This is how it works.
When an application pretty-prints a structure, it calls
special output
procedures to mark which parts of the output logically belong
together (a logical block
),
and where line-breaks and indentation may be inserted.
In Kawa the default print formatting for lists and vectors automatically calls
these procedures when the output is a pretty-printing stream
.
The pretty-printing library calculates where to put line-breaks and indentation,
based on these commands and the specified line length.
However, when the output stream is a DomTerm terminal, Kawa's pretty-printing library does not actually calculate the line-breaks. Instead it encodes the above-mentioned procedure calls as special escape sequences that get sent to DomTerm.
When DomTerm receives these escape sequences, it builds a nested DOM structure that corresponds to the orginal procedure calls. DomTerm calculates how to layout that structure using a variant of the Common Lisp pretty-printing algorithm, inserting soft left-breaks and indentation as needed.
When DomTerm detects that its window has been re-sized or zoomed, it first removes old soft line-breaks and identation. It does re-runs the layout algorithm.
When a page is saved, the nested DOM structure is written out too. If the saved page is loaded in a browser, and the necessary JavaScript libraries are available, then the pretty-printing algorithm is run on the saved page, both on initial load, and whenever the window is re-sized.
Hyphenation and word-breaking
DomTerm supports general soft (optional) line breaks: You can specify separate texts (optionally with styling) for each of the following: The text used when the line is not broken at that point; the text to use before the line-break, when broken (commonly a hyphen); the text to use after the line-break (following indentation). One use for this words that change their spelling when hyphenated, as may happen in German. For example the wordbackenbecomes
bak-ken. You can handle this using
ckk-kjava.lang.Process and java.lang.ProcessBuilder.
However, they're not as convenient as
as the old Bourne shell, or as elegant in composing commands.
If we ignore syntax, the shell's basic model is that a command is a function that takes an input string (standard input) along with some string-valued command-line arguments, and whose primary result is a string (standard output). The command also has some secondary outputs (including standard error, and the exit code). However, the elegance comes from treating standard output as a string that can be passed to another command, or used in other contexts that require a string (e.g. command substitution). This article presents how Kawa solves this problem.
Process is auto-convertable to string
To run a command like date,
you can use the run-process procedure:
#|kawa:2|# (define p1 (run-process "date --utc"))Equivalently you can use the
&`{command}
syntactic sugar:
#|kawa:2|# (define p1 &`{date --utc})
But what kind of value is p1?
It's an instance of gnu.kawa.functions.LProcess,
which is a class that extends java.lang.Process.
You can see this if you invoke toString or call the
write procedure:
#|kawa:2|# (p1:toString) gnu.kawa.functions.LProcess@377dca04 #|kawa:3|# (write p1) gnu.kawa.functions.LProcess@377dca04
An LProcess is automatically converted to
a string or a bytevector in a context that requires it.
More precisely, an LProcess
can be converted to a blob
because it implements Lazy<Blob>.
This means you can convert to a string (or bytevector):
#|kawa:9|# (define s1 ::string p1) #|kawa:10|# (write s1) "Wed Jan 1 01:18:21 UTC 2014\n" #|kawa:11|# (define b1 ::bytevector p1) (write b1) #u8(87 101 100 32 74 97 110 ... 52 10)
However the display procedure prints it in "human" form,
as a string:
#|kawa:4|# (display p1) Wed Jan 1 01:18:21 UTC 2014
This is also the default REPL formatting:
#|kawa:5|# &`{date --utc}
Wed Jan 1 01:18:22 UTC 2014
Command arguments
The general form for run-process is:
(run-process keyword-argument... command)
The command is the process command-line. It can be an array of strings, in which case those are used as the command arguments directly:
(run-process ["ls" "-l"])The command can also be a single string, which is split (tokenized) into command arguments separated by whitespace. Quotation groups words together just like traditional shells:
(run-process "cmd a\"b 'c\"d k'l m\"n'o") ⇒ (run-process ["cmd" "ab 'cd" "k'l m\"no"])
Using string templates is more readable as it avoids having to quote quotation marks:
(run-process &{cmd a"b 'c"d k'l m"n'o})
You can also use the abbreviated form:
&`{cmd a"b 'c"d k'l m"n'o}
This syntax is the same as
of SRFI-108 named quasi-literals.
In general, the following are roughly equivalent
(the difference is that the former does smart quoting of embedded expressions,
as discussed later):
&`{command}
(run-command &{command})
Similarly, the following are also roughly equivalent:
&`[keyword-argument...]{command}
(run-command keyword-argument... &{command})
A keyword-argument can specify various properties of the process. For example you can specify the working directory of the process:
(run-process directory: "/tmp" "ls -l")You can use the
shell keyword to
specify that we want to use the shell to
split the string into arguments.
For example:
(run-process shell: #t "command line")is equivalent to:
(run-process ["/bin/sh" "-c" "command line"])You can can also use the abbreviation
&sh:
&sh{rm *.class}
which is equivalent to:
&`{/bin/sh -c "rm *.class"}
In general, the abbreviated syntax:
&sh[args...]{command}
is equivalent to:
&`[shell: #t args...]{command}
Command and variable substitution
Traditional shells allow you to insert the output from a command into the command arguments of another command. For example:echo The directory is: `pwd`The equivalent Kawa syntax is:
&`{echo The directory is: &`{pwd}}
This is just a special case of substituting the result from evaluating an expression. The above is a short-hand for:
&`{echo The directory is: &[&`{pwd}]}
In general, the syntax:
...&[expression]...evaluates the
expression,
converts the result to a string, and combines it with the literal string.
(We'll see the details in the next section.)
This general form subsumes command substitution,
variable substitution, and arithmetic expansion.
Tokenization of substitution result
Things gets more interesting when considering the interaction between substitution and tokenization. This is not simple string interpolation. For example, if an interpolated value contains a quote character, we want to treat it as a literal quote, rather than a token delimiter. This matches the behavior of traditional shells. There are multiple cases, depending on whether the interpolation result is a string or a vector/list, and depending on whether the interpolation is inside a quotes.
- If the value is a string, and we're not inside
quotes, then all non-whitespace characters (including quotes) are literal,
but whitespace still separates tokens:
(define v1 "a b'c ") &`{cmd x y&[v1]z} ⟾ (run-process ["cmd" "x" "ya" "b'c" "z"]) - If the value is a string, and we are inside
single quotes, all characters (including whitespace) are literal.
&`{cmd 'x y&[v1]z'} ⟾ (run-process ["cmd" "x ya b'c z"])Double quotes work the same except that newline is an argument separator. This is useful when you have one filename per line, and the filenames may contain spaces, as in the output from
find:&`{ls -l "&`{find . -name '*.pdf'}"}If the string ends with one or more newlines, those are ignored. This rule (which also applies in the previous not-inside-quotes case) matches traditional shell behavior.
- If the value is a vector or list (of strings), and we're
not inside quotes, then each element of the array becomes its own argument,
as-is:
(define v2 ["a b" "c\"d"]) &`{cmd &[v2]} ⟾ (run-process ["cmd" "a b" "c\"d"])However, if the enclosed expression is adjacent to non-space non-quote characters, those are prepended to the first element, or appended to the last element, respectively.&`{cmd x&[v2]y} ⟾ (run-process ["cmd" "xa b" "c\"dy"]) &`{cmd x&[[]]y} ⟾ (run-process ["cmd" "xy"])This behavior is similar to how shells handle"$@"(or"${name[@]}"for general arrays), though in Kawa you would leave off the quotes.Note the equivalence:
&`{&[array]} ⟾ (run-process array) -
If the value is a vector or list (of strings), and
we are inside quotes, it is equivalent to interpolating
a single string resulting from concatenating the elements
separated by a space:
&`{cmd "&[v2]"} ⟾ (run-process ["cmd" "a b c\"d"])This behavior is similar to how shells handle
"$*"(or"${name[*]}"for general arrays). -
If the value is the result of a call to
unescaped-datathen it is parsed as if it were literal. For example a quote in the unescaped data may match a quote in the literal:(define vu (unescaped-data "b ' c d '")) &`{cmd 'a &[vu]z'} ⟾ (run-process ["cmd" "a b " "c" "d" "z"]) -
If we're using a shell to tokenize the command,
then we add quotes or backslashes as needed so that
the shell will tokenize as described above:
&sh{cmd x y&[v1]z} ⟾ (run-process ["/bin/sh" "-c" "cmd x y'a' 'b'\\'''c' z'"])
&`{command}.
You can of course use string templates with run-process:
(run-process &{echo The directory is: &`{pwd}})
However, in that case there is no smart tokenization: The template
is evaluated to a string, and then the resulting string is tokenized,
with no knowledge of where expressions were substituted.
Input/output redirection
You can use various keyword arguments to
specify standard input, output, and error streams. For example
to lower-case the text in in.txt, writing
the result to out.txt, you can do:
&`[in-from: "in.txt" out-to: "out.txt"]{tr A-Z a-z}
or:
(run-process in-from: "in.txt" out-to: "out.txt" "tr A-Z a-z")
These options are supported:
in: value- The
valueis evaluated, converted to a string (as if usingdisplay), and copied to the input file of the process. The following are equivalent:&`[in: "text\n"]{command} &`[in: &`{echo "text"}]{command}You can pipe the output from
command1to the input ofcommand2as follows:&`[in: &`{command1}]{command2} in-from:path- The process reads its input from the specified path,
which can be any value coercible to a
filepath. out-to:path- The process writes its output to the specified path.
err-to:path- Similarly for the error stream.
out-append-to:patherr-append-to:path-
Similar to
out-toanderr-to, but append to the file specified by path, instead of replacing it. in-from: 'pipeout-to: 'pipeerr-to: 'pipe- Does not set up redirection.
Instead, the specified stream is available using the methods
getOutputStream,getInputStream, orgetErrorStream, respectively, on the resultingProcessobject, just like Java'sProcessBuilder.Redirect.PIPE. in-from: 'inheritout-to: 'inheriterr-to: 'inherit- Inherits the standard input, output, or error stream from the current JVM process.
out-to: porterr-to: port- Redirects the standard output or error of the process
to the specified
port. out-to: 'currenterr-to: 'current- Same as
out-to: (current-output-port), orerr-to: (current-error-port), respectively. in-from: portin-from: 'current- Re-directs standard input to read from the
port (or
(current-input-port)). It is unspecified how much is read from the port. (The implementation is to use a thread that reads from the port, and sends it to the process, so it might read to the end of the port, even if the process doesn't read it all.) err-to: 'out- Redirect the standard error of the process to be merged with the standard output.
The default for the error stream (if neither err-to
or err-append-to is specifier) is equivalent
to err-to: 'current.
Note:
Writing to a port is implemented by copying
the output or error stream of the process.
This is done in a thread, which means we don't have any
guarantees when the copying is finished.
A possible approach is to have to process-exit-wait
(discussed later) wait for not only the process to
finish, but also for these helper threads to finish.
Here
documents
A here document
is a form a literal string, typically multi-line, and
commonly used in shells for the standard input of a process.
Kawa's string literals or string quasi-literals can be used for this.
For example, this passes the string "line1\nline2\nline3\n"
to the standard input of command:
(run-process [in: &{
&|line1
&|line2
&|line3
}] "command")
The &{...} delimits a string;
the &| indicates the preceding indentation is ignored.
Pipe-lines
Writing a multi-stage pipe-line quickly gets ugly:
&`[in: &`[in: "My text\n"]{tr a-z A-Z}]{wc}
Aside: This would be nicer in a language with in-fix operators, assuming&`is treated as a left-associative infix operator, with the input as the operational left operand:"My text\n" &`{tr a-z A-Z} &`{wc}
The convenience macro pipe-process makes this much nicer:
(pipe-process
"My text\n"
&`{tr a-z A-Z}
&`{wc})
All but the first sub-expressions must be (optionally-sugared)
run-process forms.
The first sub-expression is an arbitrary expression
which becomes the input to the second process expression;
which becomes the input to the third process expression;
and so on. The result of the pipe-process
call is the result of the last sub-expression.
Copying the output of one process to the input of the next is optimized: it uses a copying loop in a separate thread. Thus you can safely pipe long-running processes that produce huge output. This isn't quite as efficient as using an operating system pipe, but is portable and works pretty well.
Setting the process environment
By default the new process inherits the system environment of the current (JVM) process as returned bySystem.getenv(),
but you can override it.
env-name: value-
In the process environment, set the
"name"to the specifiedvalue. For example:&`[env-CLASSPATH: ".:classes"]{java MyClass} NAME: value-
Same as using the
env-nameoption, but only if theNAMEis uppercase (i.e. if uppercasingNAMEyields the same string). For example the previous example could be written:(run-process CLASSPATH: ".:classes" "java MyClass")
environment: env-
The
envis evaluated and must yield aHashMap. This map is used as the system environment of the process.
Process-based control flow
Traditional shell provides logic control flow operations based on the exit code of a process: 0 is success (true), while non-zero is failure (false). Thus you might see:
if grep Version Makefile >/dev/null then echo found Version else echo no Version fi
One idea to have a process be auto-convertible to a boolean,
in addition to be auto-convertible to strings or bytevectors:
In a boolean context, we'd wait for the process to finish,
and return #t if the exit code is 0,
and #f otherwise. This idea may be worth exploring later.
Currently Kawa provides process-exit-wait
which waits for a process to exit, and then returns the
exit code as an int.
The convenience function process-exit-ok?
returns true iff process-exit-wait returns 0.
(process-exit-wait (run-process "echo foo")) ⟾ 0The previous
sh example could be written:
(if (process-exit-ok? &`{grep Version Makefile})
&`{echo found}
&`{echo not found})
Note that unlike the sh, this ignores the
output from the grep (because no-one has asked for it).
To match the output from the shell, you can use out-to: 'inherit:
(if (process-exit-ok? &`[out-to: 'inherit]{grep Version Makefile})
&`{echo found}
&`{echo not found})
get the contents of a fileas a value, using a simple function, without using a port or looping. Kawa has a function to do that:
(path-data path)The path can be a
Path object,
or anything that can be converted to a Path, including
a filename string or a URL.
You can also use the following syntactic sugar, which is an example of SRFI-108 named quasi-literals:
&<{pname}
This syntax is meant to suggest the shell input redirection operator
<pname.
The meaning of &<{pname} is the same as
(path-data &{pname}),
where &{pname} is a
SRFI-109 string quasi-literal. (This is almost the same as (path-data "pname")
using a traditional string literal, except for the rules for quoting and escaping.)
What kind of object is returned by &<{pname}?
And what is printed when you type that at the REPL?
Fundamentally, in modern computers the contents of a file is
a sequence of uninterpreted bytes.
Most commonly, these bytes represent text in a locale-dependent encoding,
but we don't always know this. Sometimes they're images, or videos,
or word-processor documents. It's like writing assembly code:
you have to know the types of your values.
At best we can guess at the type of a file
based on its name or extension or looking for magic numbers.
So unless we have more information, we'll say that
path-data returns a
blob,
and we'll implementing it using the gnu.lists.Blob type.
$ cat README
Check doc directory.
$ kawa
#|kawa:1|# (define readme &<{README})
#|kawa:2|# readme:class
class gnu.lists.Blob
You can explicitly coerce a Blob to a string or to a bytevector:
#|kawa:3|# (write (->string readme)) "Check doc directory.\n" #|kawa:4|# (write (->bytevector readme)) #u8(67 104 101 99 107 32 100 111 99 32 100 105 114 101 99 116 111 114 121 46 10) #|kawa:5|# (->bytevector readme):class class gnu.lists.U8Vector
The output of a command (which we'll discuss in the next article): is also a blob. For almost all programs, standard output is printable text, because if you try to run a program without re-direction, and it spews out binary data, it may mess up your terminal, which is annoying. Which suggests an answer to what happens when you get a blob result in the REPL: The REPL should try to print out the contents as text, converting the bytes of the blob to a string using a default encoding:
#|kawa:6|# &<{README}
Check doc directory.
It makes sense look at the bytes to see if we can infer an encoding,
especially on Windows which doesn't use a default encoding.
Currently Kawa checks for a
byte-order mark;
more sniffingis likely to be added later.
What if the file is not a text file?
It might be reasonable to be able to configure
a handler for binary files.
For example for a .jpg image file,
if the the console can display images, it makes sense to display
the image inline. It helps if the blob has a known MIME type.
(I believe a rich text console should be built using web browser technologies,
but that's a different topic.)
Writing to a file
The &<{..} operation can be used with set!
to replace the contents of a file:
(set! &<{README} "Check example.com\n")
If you dislike using
as an output operator,
you can instead using the <&>{..} operation,
which evaluates to function whose single argument is the new value:
(&>{README} "Check example.com\n")
You can use &>> to append more data to a file:
(&>>{README} "or check example2.com\n")
The current directory
Functions like path-data or open-input-file
or the sugar
we seen above all use the current directory
as a base directory for relative pathname. You get the
current value of the current directory with the expression
(current-path).
This returns a path object, which prints as the string value of the path.
The initial value of (current-path) is the
value of the "user.dir" property,
but you change it using a setter:
(set! (current-path) "/opt/myApp/")A string value is automatically converted to a
path,
normally a filepath.
The procedure current-path is a
parameter,
so you can alternatively call it with the new value:
(current-path "/opt/myApp/")You can also use the
parameterize form:
(parameterize ((current-path "/opt/myApp/"))
(list &<{data1.txt} &<{data2.txt}))
ftp://ftp.gnu.org/pub/gnu/kawa/kawa-1.14.tar.gz (source code)
ftp://ftp.gnu.org/pub/gnu/kawa/kawa-1.14.jar (runnablejar)
For a extended list of changes, see the news page. Below are some highlights.
More R7RS functions
The proposed new standard for Scheme R7RS has a number of new functions, and also extensions to existing functions. Kawa 1.14 implements (and documents) most of the new functions and extensions, and also implements a number of the syntactic changes:
make-list, list-copy,
list-set! all the R7RS list procedures are implemented.
square,
boolean=?, string-copy!,
digit-value,
get-environment-variable, get-environment-variables,
current-second, current-jiffy,
jiffies-per-second, and features.
finite?, infinite?, and
nan? are generalized to complex numbers.
write, write-simple,
and write-shared are now consistent with R7RS.
string-copy, string->list,
and string-fill! now take optional (start,end)-bounds.
All of the R7RS string functions are now implemented.
=> syntax in case form.
'|Hello\nworld|.
The most important functionality still missing is support for the
library (module) system, and specifically the define-library
form. Of course Kawa has its own powerful
module system
which is in spirit quite compatible, but we still need to decide on the
pragmatic issues, including how modules are resolved to files
(probably using a module search path), and translation to class names.
Another feature to ponder is how to handle the R7RS exception
mechanism, and how it maps to JVM exceptions. We probably won't
implement all of the R7RS semantics, but it would be desirable
if (for example) some simple uses of guard would work on Kawa.
Better support for multi-line strings and templates
SRFI-109 specifies a syntax for quasi-literal strings. These have a numbers of advantages over traditional double-quote literals. The are quasi-literals in the sense that they can contain embedded expressions. For example, ifname has the value "John", then:
&{Hello &[name]!}
evaluates to "Hello John!".
Other benefits include control over indentation (layout),
built-in support for format specifiers,
and a huge number of named special characters.
See the documentation and the
SRFI-109 specification for details.
Named quasi-literals (SRFI-108)
SRFI-108 can be viewed as a generalization of SRFI-109, in that the constructors have names, and you can define new constructors. This could be used for writing documentation (similar to the Scribble system), or constructing complex nested data structures (a generalization of XML).Better support for command scripts
A number of little improvements have been made to make it easier to write Kawa command scripts (simple one-file applications). Most importantly the documentation has been re-written. The value returned by(car (command-line))
(i.e. the "name" of the script/command invoked) is now accurate and
useful in many more cases; you also have the option of setting explicitly
it with the -Dkawa.command.name option.
Experimental Java 8 support
There is some very preliminary support for next year's Java 8.
These are enabled if you run configure with
the --with-java-source=8 (or if ant
auto-detects java.util.stream.Stream).
This flag doesn't yet do very much:
- It sets the classfile major version number.
- It adds an optimized version of the
Stream#forEachmethod forgnu.lists.SimpleVectorand its subclasses, which includes theFVectorused to implement Scheme vectors. - Enhance
gnu.lists.Consumerto implementjava.util.function.Consumerand the specialized classesjava.util.function.{Int,Long,Double}Consumer.Because output port implements
gnu.lists.Consumer, this means you can pass a port to theforEachmethod:#|kawa:11|# ((['a 'b 'c 'd]:stream):forEach (current-output-port)) a b c d
Of course a large extent streams just Work Out of the Box
with Kawa data types, because they implement the apropriate
Java interfaces. For examples lists and vectors both implement
java.util.List, and thus they automatically have
the stream method.
Read JavaFX-using-Kawa-intro first. That introduces JavaFX and how you can use Kawa to write rich GUI applications.
This example demonstrates simple animation: A rectangle that moves
smoothly left to right and back again continuously.
This is example is converted from HelloAnimation.java written in Java by Kevin Rushforth. Here is the entire program HelloAnimation.scm:
(require 'javafx-defs) (javafx-application) (define rect (Rectangle x: 25 y: 40 width: 100 height: 50 fill: Color:RED)) (javafx-scene title: "Hello Animation" width: 600 height: 450 fill: Color:LIGHTGREEN rect) ((Timeline cycle-count: Timeline:INDEFINITE auto-reverse: #t (KeyFrame (Duration:millis 500) (KeyValue (rect:xProperty) 200))):play)
The first two lines are boilerplate, as in JavaFX-using-Kawa-intro.
The (define rect (Rectange ...)) defines a variable
rect, and initializes it to a new Rectangle,
using an object constructor as seen before.
The (javafx-scene ...) operations creates the scene with
the specified title, width, height
and fill (background color) properties.
It adds the rect to the scene, and then creates a window to make it visible.
Finally, we animate rect. This requires some background explanation.
Key values and key frames
To animate a scene you create a TimeLine data structure,
which describes what properties to modify and when to do so.
Once you have done so, call play on the TimeLine,
which instructs JavaFX's animation engine to start running the animation.
In this example, the animation continuous indefinitely:
When done, it reverses (because auto-reverse was set to true)
and starts over.
The timeline is divided into a fixed number of
key frames,
which are associated with a specific point in time.
In the current example there is the implicit starting key-frame
at time 0, and an explicit key-frame at time 500 (milliseconds).
(The KeyFrame specifies a duration or ending time,
where the start time is the ending time of the previous key-frame,
or 0 in the case of the first key-frame.)
The animator (or programmer) specifies various properties (such
as positions and sizes of objects) at each key-frame, and then the
computer smoothly interpolates between the key-frames.
By default the interpolation is linear, but you can specify other
kinds of interpolation.
Each KeyFrame consists of some KeyValue objects.
A KeyValue species which property to modify
and the ending value that the property will have at the end of the key-frame.
In the example, we have a single KeyValue to modify
rect:x, ending at 200. (The start value is 25, as set when
rect was constructed.)
In JavaFX, the properties to animate are specified using
Property objects. Typeically, a property is a reference
to a specific field in a specific object instance. You register the
property with the animation engine (as shown in the sample), and then
the animation engine uses the property to modify the field.
In the example the expression (rect:xProperty)
(equivalent to the Java method call rect.xProperty())
returns a property that references the x property
of the rect object.
The Property object also has ways to register dependencies
(rather like change listeners) so that things get updated
when the property is changed. (For example the rectangle is re-drawn
when its x property changes.)
Here is a static screenshot - obviously an animiated gif would be nicer here!
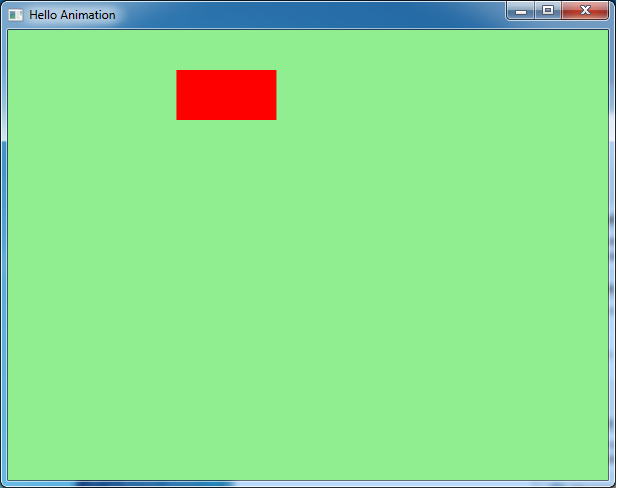
More information
ToDo: Links to documentation and other JavaFX examples.JavaFX 1.0 was a next-generation GUI/client platform. It had a new Node-based GUI API and used a new language, JavaFX Script, whose goal was to make it easier to program Rich Client applications. (Yours truly was hired by Sun to work on the JavaFX Script compiler.) In 2010 the JavaFX Script language was cancelled: JavaFX would still refer to a new GUI based API based on many of the same concepts, but the primary programming language would be Java, rather than JavaFX Script.
Java is a relatively low-level and clumsy language for writing Rich Client appliations, though it's not too painful. Still, there was a reason we worked on JavaFX Script: It had a number of features to make such programs more convenient. Luckily, other JVM languages - and specifically Kawa-Scheme - can take up the slack. Below I'll show you a simple Hello-World-type example, and then explain how you can try it yourself. In later acticles I'll show different examples.
Simple buttons and events
Our first example is just 3 buttons and 2 trivial event handlers. It is translated from HelloButton.java written in Java by Richard Bair.
(require 'javafx-defs) (javafx-application) (javafx-scene title: "Hello Button" width: 600 height: 450 (Button text: "Click Me" layout-x: 25 layout-y: 40 on-action: (lambda (e) (format #t "Event: ~s~%" e)) on-key-released: (lambda (e) (format #t "Event: ~s~%" e))) (Button text: "Click Me Too" layout-x: 25 layout-y: 70) (Button text: "Click Me Three" layout-x: 25 layout-y: 100))
For those new to Scheme, the basic syntactic building block has the form:
(operator argument1 ... argumentN)The
operator can be a function (like format),
an arithmetic operator in prefix form (like (+ 3 4)),
a command, a keyword (like lambda), or a user-defined macro.
This general format makes for a lot of flexibility.
The first two lines in HelloButton.scm are boiler-plate:
The require imports various definitions and aliases,
while the (javafx-application) syntax declares
this module is a JavaFX Application.
The javafx-scene form (a macro) creates a scene,
which is a collection of graphical objects.
The Scene has certain named properties (title,
width, and height), specified using keyword arguments. The Scene also has 3 Button children.
Finally, the make-scene command puts the scene
on the stage (the window) and makes it visible.
Each Button form is an object constructor. For example:
(Button text: "Click Me Three" layout-x: 25 layout-y: 100)is equivalent to the Java code:
javafx.scene.control.Button tmp = new javafx.scene.control.Button();
tmp.setText("Click Me Three");
tmp.setLayoutX(25);
tmp.setLayoutY(100);
return tmp;
The on-action and on-key-released
properties on the first Button bind event handlers.
Each handler is a lambda expression or anonymous function that takes an event e as a parameter. The Kawa compiler converts the handler to a suitable
event handler object using
SAM-conversion features
.
(This conversion depends on the context, so if you don't have a
literal lambda expression you have to do the conversion by hand
using an object operator.)
Getting it to run
Downloading JavaFX 2.x beta
For now JavaFX is only available for Windows, but Mac and GNU/Linux ports are being worked on and mostly work. (I primarily use Fedora Linux.) The primary JavaFX site has lots of information, including a link to the download site. You will need to register, as long the software is beta. Download the zipfile and extract it to some suitable location.
In the following, we assume the variable JAVAFX_HOME
is set to the build you've installed. For example (if using plain Windows):
set JAVAFX_HOME=c:\javafx-sdk2.0-betaThe file
%JAVAFX_HOME%\rt\lib\jfxrt.jar should exist.
Downloading and building Kawa
The JavaFX support in Kawa is new and experimental (and unstable), so for now you will have to get the Kawa source code from SVN.
There are two ways to build Kawa. The easiest is to use Ant - on plain Windows do:
ant -Djavafx.home=%JAVAFX_HOME%or on other platforms (including Cygwin):
ant -Djavafx.home=$JAVAFX_HOME
Alternatively, you can use configure and make
(but note that on Windows you will need to have Cygwin installed to use this approach):
$ KAWA_DIR=path_to_Kawa_sources $ cd $KAWA_DIR $ ./configure --with-javafx=$JAVAFX_HOME $ make
Running the example
On Windows, the easiest way to run the example is to use the
kawa.bat created when building Kawa. It sets up
the necessary paths for you.
%KAWA_HOME%\bin\kawa.bat HelloButton.scm
On Cygwin (or Unix/Linux) you can use the similar kawa.sh.
I suggest setting your PATH to find
kawa.bat or kawa.sh, so you can just do:
kawa HelloButton.scm
Using the kawa command is equivalent to
java -classpath classpath kawa.repl HelloButton.scmbut it sets the classpath automatically. If you do it by hand you need to include
%JAVAFX_HOME%\rt\lib\jfxrt.jar
and %KAWA_DIR%\kawa-version.jar.
This is what pops up:
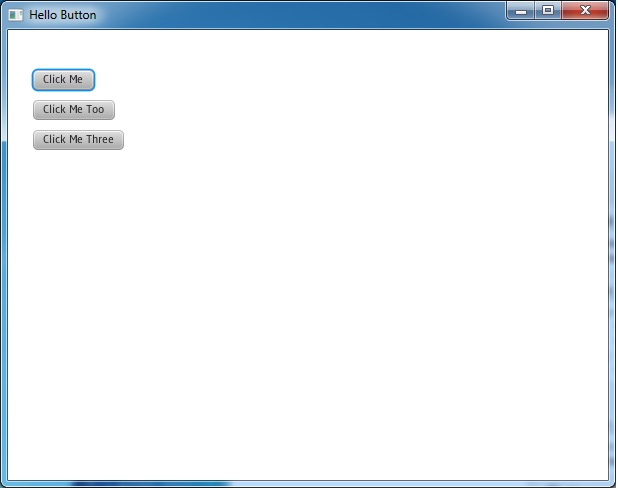
If you click the first button the action event fires, and
you should see something like:
Event: javafx.event.ActionEvent[source=Button@3a5794[styleClass=button]]
If you type a key (say n) while that button has focus
(e.g. after clicking it),
then when you release the key a key-released event fires:
Event: KeyEvent [source = Button@3a5794[styleClass=button], target = Button@3a5794[styleClass=button], eventType = KEY_RELEASED, consumed = false, character = , text = n, code = N]
Note: Running a JavaFX application from the Kawa read-eval-print-loop (REPL) doesn't work very well at this point, but I'm exploring ideas to make it useful.
Compiling the example
You can compile HelloButton.scm to class files:
kawa --main -C HelloButton.scm
You can execute the resulting application in the usual way:
java -classpath classpath HelloButtonor use the
kawa command:
kawa HelloButton
Next
JavaFX-using-Kawa-animation(This has been updated here.)
Google's phone operating system "Android" is based on a custom Java virtual machine on top of GNU/Linux. So it occurred to me: How difficult would it be to get a Kawa application running on Android? Not that difficult, it turns out.
Here is "Hello world" written in Kawa Scheme:
(module-extends android.app.Activity)
(module-name kawa.android.hello)
(define (onCreate (savedInstanceState :: android.os.Bundle)) :: void
(invoke-special android.app.Activity (this) 'onCreate savedInstanceState)
(let ((tv :: android.widget.TextView (make android.widget.TextView (this))))
(tv:setText "Hello, Android from Kawa Scheme!")
((this):setContentView tv)))
It's got some annoying boiler-plate, though it's similar to the Java version; hopefully we can simplify later.
Here is how to get this program running on the Android emulator on GNU/Linux. (I haven't yet figured out how to get it working on the actual phone.) This article Android Phone development from the Linux command-line was helpful in figuring out what to do.
First you need to download the Android SDK. Unzip, in a suitable location,
which we'll refer to as ANDROID_HOME:
ANDROID_HOME=/path/to/android-sdk-linux_x86-1.0_r2 PATH=$ANDROID_HOME/tools:$PATH
To get this to work I had to make some modest changes to Kawa, so you will need to get the Kawa developer sources from SVN.
You need to configure and make Kawa appropriately:
KAWA_DIR=path_to_Kawa_sources cd $KAWA_DIR ./configure --with-android=$ANDROID_HOME/android.jar make
Next, we need to create a project or activity,
in the target directory KawaHello,
with the main activity
being a class named hello
in a package kawa.android:
activitycreator --out KawaHello kawa.android.hello
Replace the skeleton hello.java by the
Scheme code we started out with:
cd KawaHello HELLO_APP_DIR=`pwd` cd $HELLO_APP_DIR/src/kawa/android/ rm hello.java emacs hello.scm
We need to copy/link the Kawa jar file so the Android SDK can find it:
cd $HELLO_APP_DIR ln -s $KAWA_DIR/kawa-1.9.3.jar libs/kawa.jar
We also need to modify the Ant build.xml
so it knows how to compile Scheme code:
patch < build-xml.patch
Finally, we can compile our application:
ant
Next start up the Android emulator:
emulator&
Wait until Android has finished booting, clisk the menu and home buttons. Click the tab above the menu key to show the installed applications. Now install our new application:
adb install bin/hello-debug.apk
The new hello application should show up.
Click it, and you should see something like:
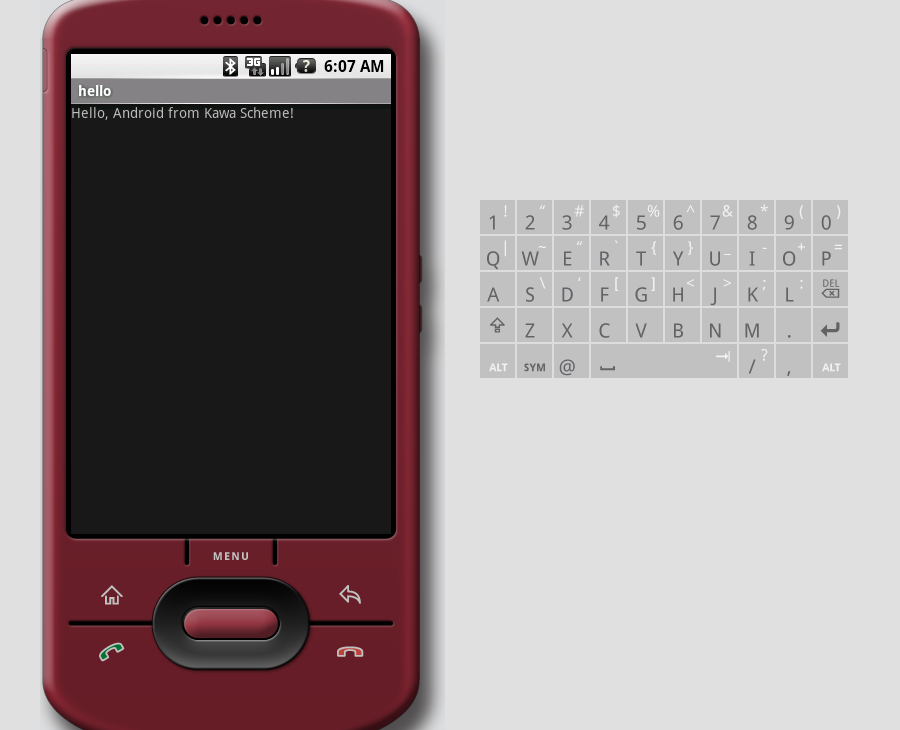
Some debugging notes
You will find a copy of the SDK documentation in
$ANDROID_HOME/docs/documentation.html.
If the emulator complains that your application
has stopped unexpectedly
, start ddms
(Dalvik Debug Monitor Service), click on the kawa.android
line in the top-left sub-window to select it, then from the
Device menu select Run logcat....
This shows log messages, stack traces, output from the Log.i
loggin method, and other useful information.
To uninstall your application, do:
adb uninstall kawa.android
(This is an update of the 2009 version, which was an update of the original 2008 version.)
Google's phone operating system "Android" is based on a custom Java virtual machine on top of GNU/Linux. So it occurred to me: How difficult would it be to get a Kawa application running on Android? Not that difficult, it turns out.
Here is "Hello world" written in Kawa Scheme:
(require 'android-defs)
(activity hello
(on-create-view
(android.widget.TextView (this)
text: "Hello, Android from Kawa Scheme!")))
(A more interesting
text-to-speech example app is on
Santosh Rajan's Android-Scheme blog.)
The following instructions have been tested on GNU/Linux, specifically Fedora 13, but if you've managed to build Android applications under (say) Windows, you should be able to appropriately modify these instructions.
Getting and building Kawa and Android
First download the Android SDK. Unzip in a suitable location,
which we'll refer to as ANDROID_HOME.
$ export ANDROID_HOME=/path/to/android-sdk-linux_86 $ PATH=$ANDROID_HOME/tools:$PATH
Next you have to get the appropriate platform SDK:
$ android update sdkSelect
SDK Platform Android 2.2 or whatever
and click Install.
You need to select an Android platform
.
Platform 8 corresponds to Android 2.2 (Froyo).
ANDROID_PLATFORM=android-8
You need to get the Kawa source code (version 1.11 or later).
Set JAVA_HOME to where your JDK tree is, for example:
$ export JAVA_HOME=/opt/jdk/1.6.0
If using Ant (as is recommended on Windows):
$ ant -Denable-android=true
Alternatively, you can use configure and make:
$ KAWA_DIR=path_to_Kawa_sources $ cd $KAWA_DIR $ ./configure --with-android=$ANDROID_HOME/platforms/$ANDROID_PLATFORM/android.jar --disable-xquery --disable-jemacs $ make
Creating the application
Next, we need to create a project or activity
,
in the target directory KawaHello,
with the main activity being a class named hello
in a package kawa.android:
$ android create project --target $ANDROID_PLATFORM --name KawaHello --activity hello --path ./KawaHello --package kawa.android
Replace the skeleton hello.java by the
Scheme code at the top of this note:
$ cd KawaHello $ HELLO_APP_DIR=`pwd` $ cd $HELLO_APP_DIR/src/kawa/android/ $ rm hello.java $ emacs hello.scm
We need to copy/link the Kawa jar file so the Android SDK can find it:
$ cd $HELLO_APP_DIR $ ln -s $KAWA_DIR/kawa-1.10.jar libs/kawa.jar
Optionally, you can use kawart-1.10.jar, which is
slightly smaller, but does not support eval,
and does not get built by the Ant build:
$ ln -s $KAWA_DIR/kawart-1.10.jar libs/kawa.jar
We also need to modify the Ant build.xml
so it knows how to compile Scheme code:
$ patch < build-xml-patch.txt
Finally, we can build our application:
$ ant debug
Running the application on the Android emulator
First you need to
create an Android Virtual Device (avd).
Start:
androidthen select
Virtual Devices, then click New....
Pick a Name (we use avd8 in the following),
a Target (to match $ANDROID_PLATFORM),
and optionally change the other properties, before clicking Create AVD.
Start up the Android emulator:
$ emulator -avd avd8 &
Wait until Android has finished booting (you will see the Android home screen), click the menu and home buttons. Now install our new application:
adb install bin/KawaHello-debug.apk
The new hello application should show up.
Click it, and you should see something like:
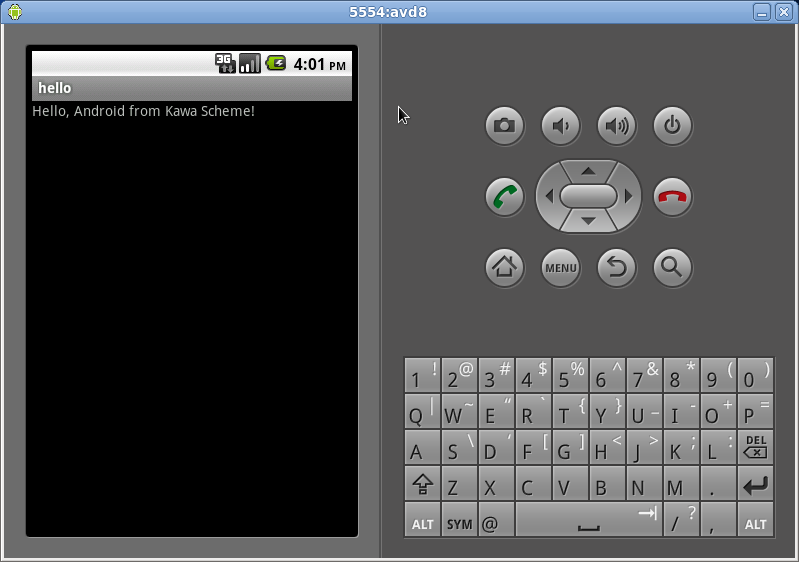
Running the application on your phone
If the emulator is running, kill it:
$ kill %emulator
On the phone, enable USB debugging. (This is settable from the
Settings application, under Applications / Development.)
Connect the phone to your computer with the USB cable.
Verify that the phone is accessible to adb:
$ adb devices List of devices attached 0A3A560F0C015024 device
If you don't see a device listed, it may be permission problem. You can figure out which device corresponds to the phone by doing:
$ ls -l /dev/bus/usb/* /dev/bus/usb/001: total 0 ... crw-rw-rw- 1 root wheel 189, 5 2010-10-18 16:52 006 ...
The timestamp corresponds to when you connected the phone. Make it readable:
$ sudo chmod a+w /dev/bus/usb/001/006
Obviously if you spend time developing for an Androd phone you'll want to automate this process; this link or this link may be helpful.
Anyway, once adb can talk to the phone, you
install in the same way as before:
adb install bin/KawaHello-debug.apk
Some debugging notes
You will find a copy of the SDK documentation in
$ANDROID_HOME/docs/index.html.
If the emulator complains that your application
has stopped unexpectedly
, do:
$ adb logcat
This shows log messages, stack traces, output from the Log.i
logging method, and other useful information.
(You can alternatively start ddms
(Dalvik Debug Monitor Service), click on the kawa.android
line in the top-left sub-window to select it, then from the
Device menu select Run logcat....)
To uninstall your application, do:
$ adb uninstall kawa.android
(Here is the latest version. This is in turn an update of the original version.)
Google's phone operating system "Android" is based on a custom Java virtual machine on top of GNU/Linux. So it occurred to me: How difficult would it be to get a Kawa application running on Android? Not that difficult, it turns out.
Here is "Hello world" written in Kawa Scheme:
(require 'android-defs)
(activity hello
(on-create-view
(let ((tv (android.widget.TextView (this))))
(tv:setText "Hello, Android from Kawa Scheme!")
tv)))
The following instructions have been tested on GNU/Linux, specifically Fedora 10, but if you've managed to build Android applications under (say) Windows, you should be able to appropriately modify these instructions. The article Android Phone development from the Linux command-line helped me figure out what to do.
Getting and building Kawa and Android
First download the Android SDK. Unzip in a suitable location,
which we'll refer to as ANDROID_HOME.
$ ANDROID_HOME=/path/to/android-sdk-linux_x86-1.0_r2 $ PATH=$ANDROID_HOME/tools:$PATH
To get things to work I had to make some modest changes to Kawa, so you will need to get the Kawa developer sources from SVN.
You need to configure and make Kawa appropriately:
$ KAWA_DIR=path_to_Kawa_sources $ cd $KAWA_DIR $ ./configure --with-android=$ANDROID_HOME/android.jar --disable-xquery $ make
Creating the application
Next, we need to create a project or activity,
in the target directory KawaHello,
with the main activity
being a class named hello
in a package kawa.android:
$ activitycreator --out KawaHello kawa.android.hello
Replace the skeleton hello.java by the
Scheme code at the top of this note:
$ cd KawaHello $ HELLO_APP_DIR=`pwd` $ cd $HELLO_APP_DIR/src/kawa/android/ $ rm hello.java $ emacs hello.scm
We need to copy/link the Kawa jar file so the Android SDK can find it:
$ cd $HELLO_APP_DIR $ ln -s $KAWA_DIR/kawa-1.9.3.jar libs/kawa.jar
We also need to modify the Ant build.xml
so it knows how to compile Scheme code:
$ patch < build-xml-patch.txt
Finally, we can compile our application:
$ ant
Running the application on the Android emulator
Start up the Android emulator:
$ emulator&
Wait until Android has finished booting, clisk the menu and home buttons. Click the tab above the menu key to show the installed applications. Now install our new application:
adb install bin/hello-debug.apk
The new hello application should show up.
Click it, and you should see something like:
Running the application on the G1 phone
If the emulator is running, kill it:
$ kill %emulator
Connect the phone to your computer with the USB cable.
Verify that the phone is accessible to adb:
$ adb devices List of devices attached HT849GZ17337 device
If you don't see a device listed, it may be permission problem. You can figure out which device corresponds to the phone by doing:
$ ls -l /dev/bus/usb/* /dev/bus/usb/001: total 0 ... crw-rw-rw- 1 root wheel 189, 5 2009-01-18 16:52 006 ...
The timestamp corresponds to when you connected the phone. Make it readable:
$ sudo chmod a+w /dev/bus/usb/001/006
Obviously if you spend time developing for an Androd phone you'll want to automate this process; this link or this link may be helpful.
Anyway, once adb can talk to the phone, you
install in the same way as before:
adb install bin/hello-debug.apk
Some debugging notes
You will find a copy of the SDK documentation in
$ANDROID_HOME/docs/documentation.html.
If the emulator complains that your application
has stopped unexpectedly
, do:
$ adb logcat
This shows log messages, stack traces, output from the Log.i
logging method, and other useful information.
(You can alternatively start ddms
(Dalvik Debug Monitor Service), click on the kawa.android
line in the top-left sub-window to select it, then from the
Device menu select Run logcat....)
To uninstall your application, do:
$ adb uninstall kawa.android